[TOC]
AI Agent是什么
- Agent英文直译是代理,又称智能体。
- 从技术角度看,
AI Agent是一个能够接收输入、进行有限决策并执行预设动作的智能程序。 - 与传统的 AI 模型相比,AI Agent 增加了任务规划和执行能力,但目前的自主性和适应性仍有限。它更像是一个”智能助手”,需要在明确的规则和边界下工作。
主要架构
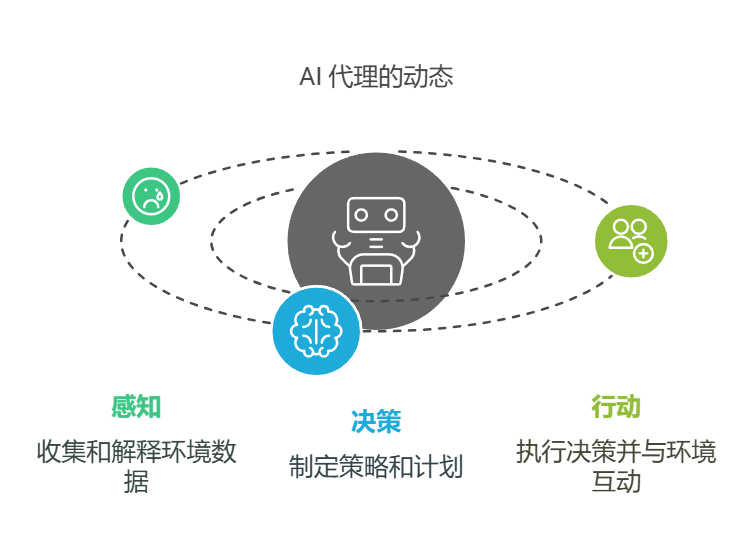
AI Agent 架构主要包含三个基础模块:
- **输入处理模块:**负责解析用户需求和环境数据。
- **推理模块:**基于预设规则和模型进行判断。
- **执行模块:**按照既定流程完成具体任务。
其他解释
Agent由三个组件组成:一个大型语言模型 (LLM)、一套可供其使用的工具以及一个提供指令的提示。
LLM 在一个循环中运行。在每次迭代中,它选择一个工具来调用,提供输入,接收结果(观察),并使用该观察来指导下一个动作。循环持续进行,直到满足停止条件——通常是当代理收集到足够的信息来响应用户时。
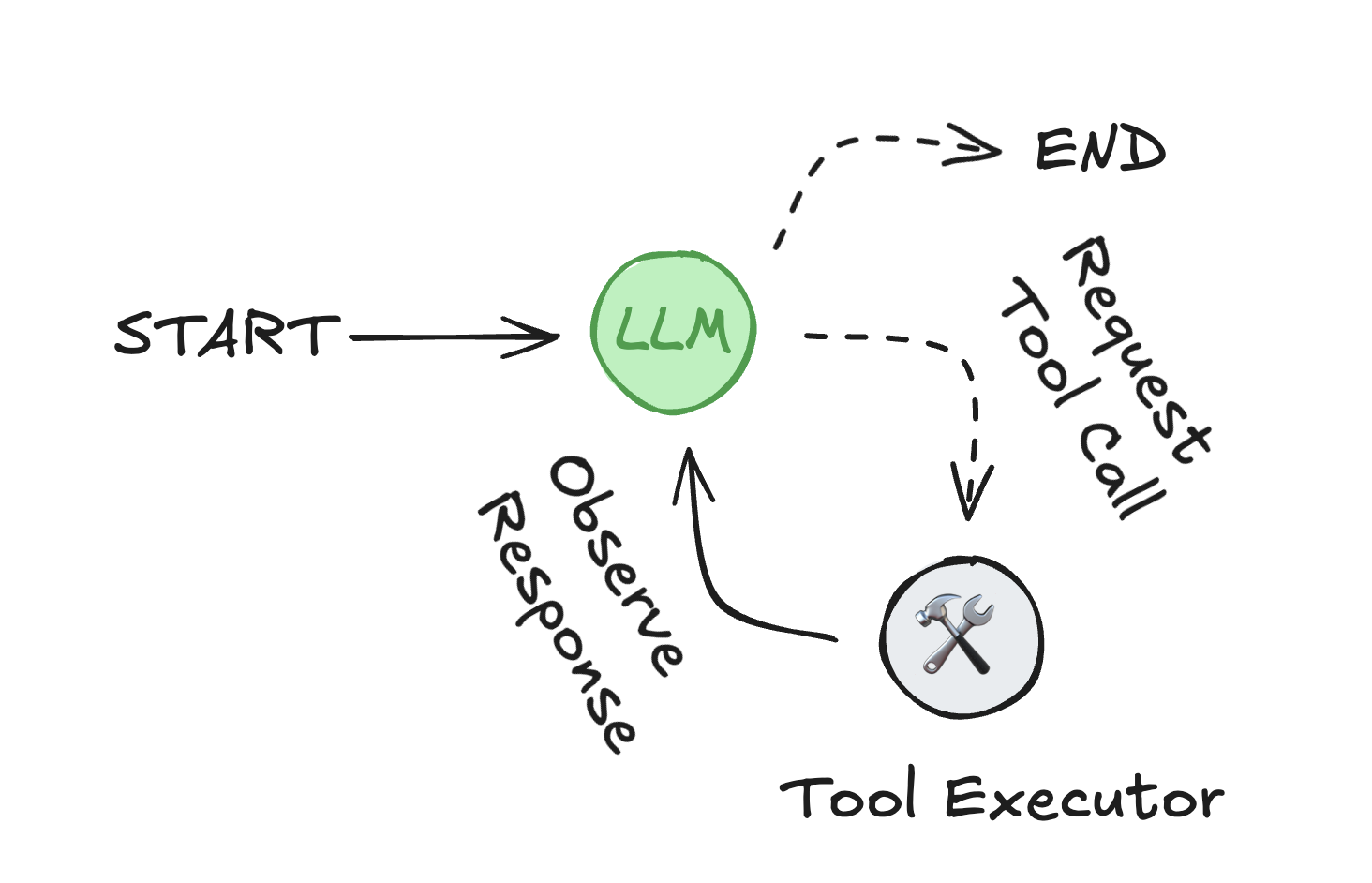
代理循环:LLM 选择工具并使用它们的输出来满足用户请求。
智能体
智能体的宏观机会


智能体重要构件
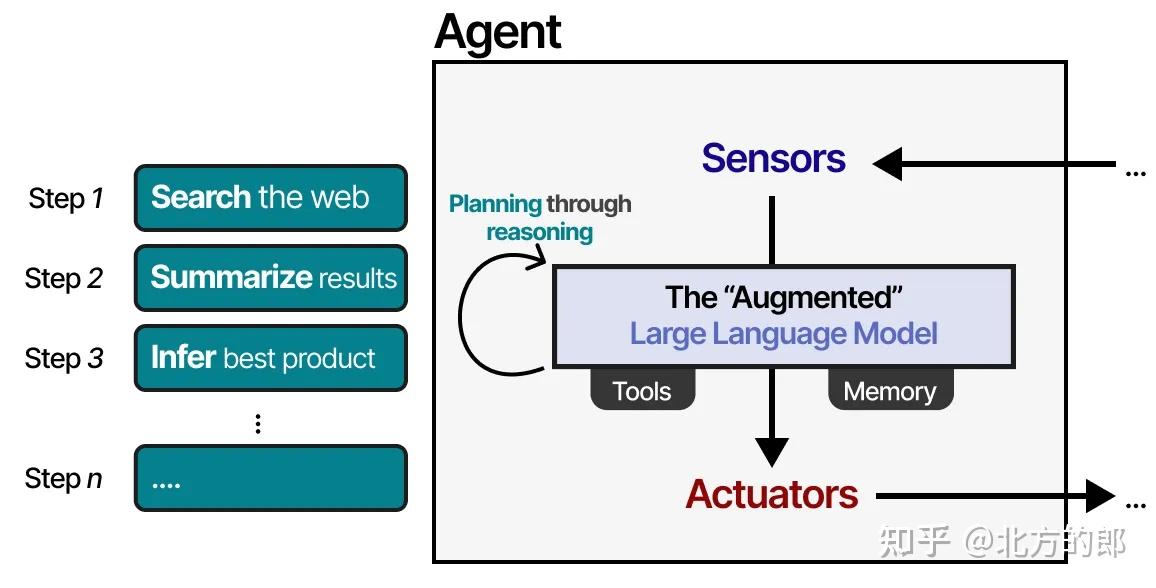
智能体与其环境互动,通常由几个重要组件构成:
- 环境(Environment):智能体所感知和影响的外部世界。
- 传感器(Sensors):感知环境状态。
- 执行器(Actuators):与环境交互的物理或虚拟接口。
- 效应器(Effectors)/策略大脑(Policy/Planner):负责从感知转化为行动的逻辑模块,包括记忆、规则、规划等。
对应到增强型LLM,可以将“环境”理解为文本世界或插件系统,“执行器”就是工具,“效应器”是模型本身的推理能力。
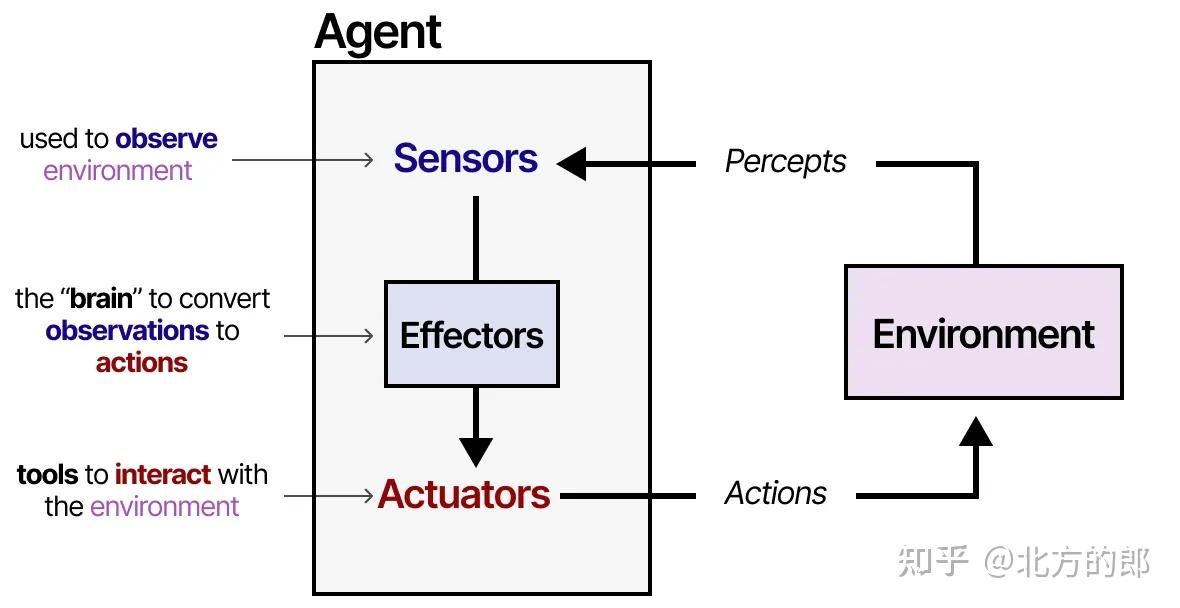
这一框架适用于各种与环境交互的智能体,例如机器人与其物理环境互动,或AI智能体与软件环境互动。
关键构件
我们可以将“增强型LLM智能体”视为一个基于大型语言模型(LLM)构建的认知系统,其关键在于:感知 → 推理/规划 → 行动 → 记忆 的闭环。
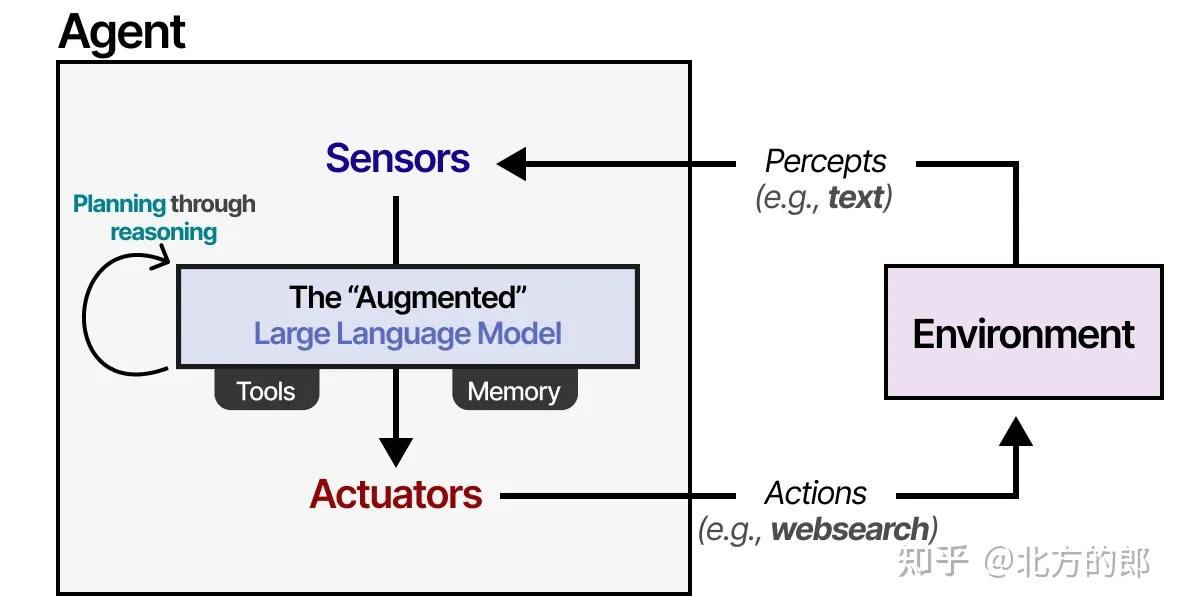
1. 感知
LLM通过自然语言输入观察环境。这种输入可以来自用户提问、传感器信息的文本化描述,或其他外部系统的语言输出。
2. 推理与规划
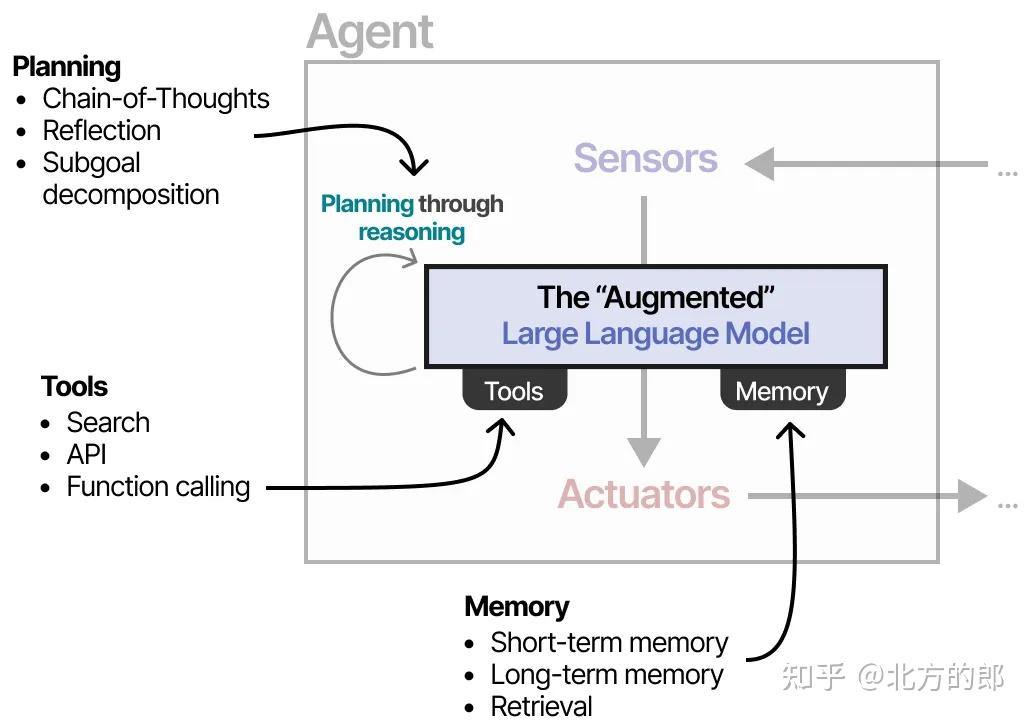
为了决定接下来的行动步骤,LLM需要具备推理能力。通过“思维链”(Chain-of-Thought, CoT)等技术,模型能够:
- 逐步分析当前环境状态
- 拆解复杂问题
- 制定多步行动计划
如下图所示:
这部分是智能体行为的核心,体现了模型的“智能性”。
3. 工具使用
LLM本身并不能直接与世界交互,因此需要通过调用工具来执行计划的行动。例如:
- 调用搜索引擎获取实时信息
- 使用计算工具处理数据
- 发送请求给外部API
4. 记忆
为了跟踪过去的观察与行动,LLM需要维持内部状态或接入外部记忆模块。这使其能够:
- 回顾先前的对话和操作
- 维持任务上下文
- 在多轮交互中保持连贯性
这种规划行为使智能体能够感知(LLM)、规划下一步(规划)、采取行动(工具),并跟踪已采取的行动(记忆)。
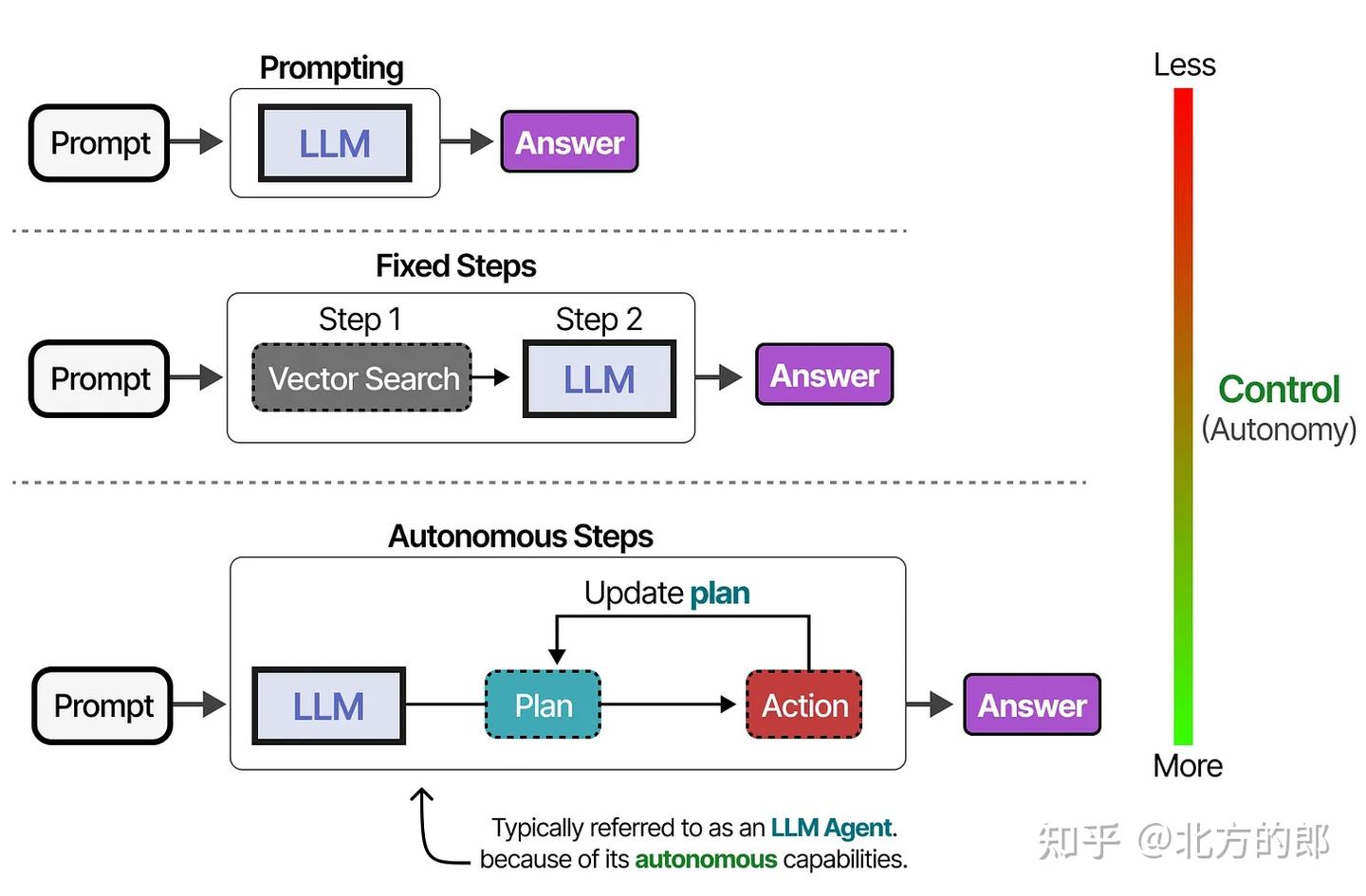
LLM智能体的自主性
根据系统的不同,LLM智能体可以拥有不同程度的自主性。
LLM智能体三大组件
记忆
短期记忆(工作记忆)
LLM是健忘的系统,或者更准确地说,与它们交互时它们根本不进行任何记忆。例如,当你向LLM提出一个问题,然后接着提出另一个问题时,它不会记住之前的问题。我们通常将此称为短期记忆,也称为工作记忆,它作为(近乎)即时上下文的缓冲区。这包括LLM智能体最近采取的行动。
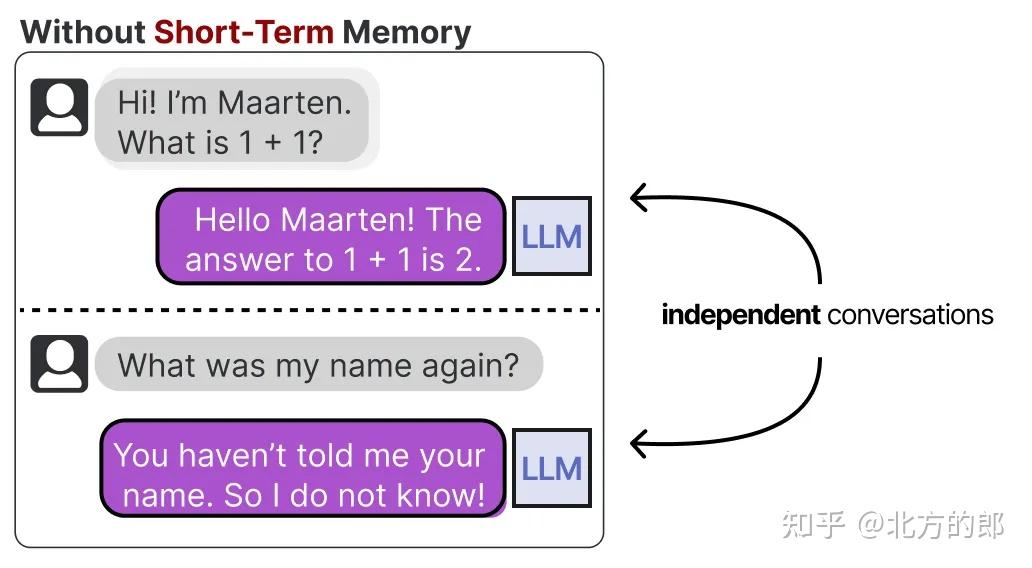
用于跟踪最近的上下文和行动
上下文窗口
启用短期记忆的最直接方法是使用模型的上下文窗口(context window),它本质上是LLM可以处理的词数(token)。
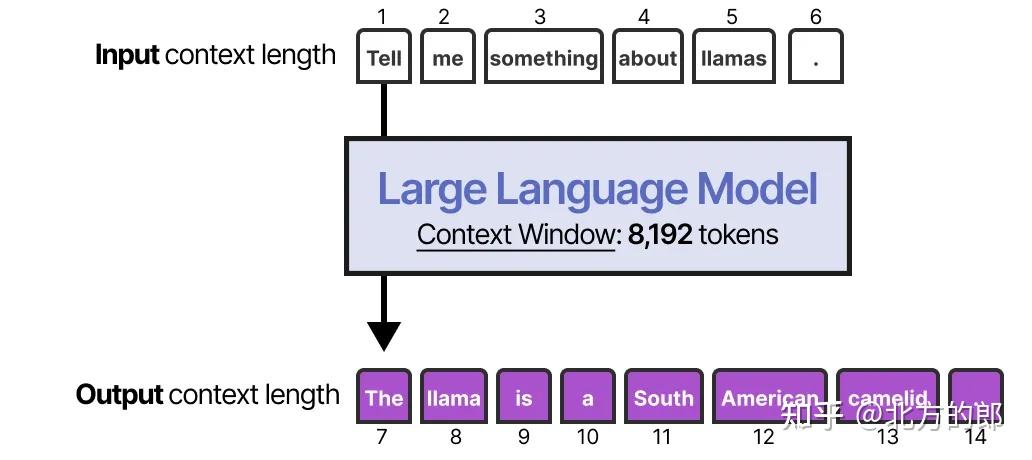
上下文窗口通常至少有8192个词,有时甚至可以扩展到数十万个词!
一个大的上下文窗口可以用来跟踪完整的对话历史,作为输入提示的一部分。
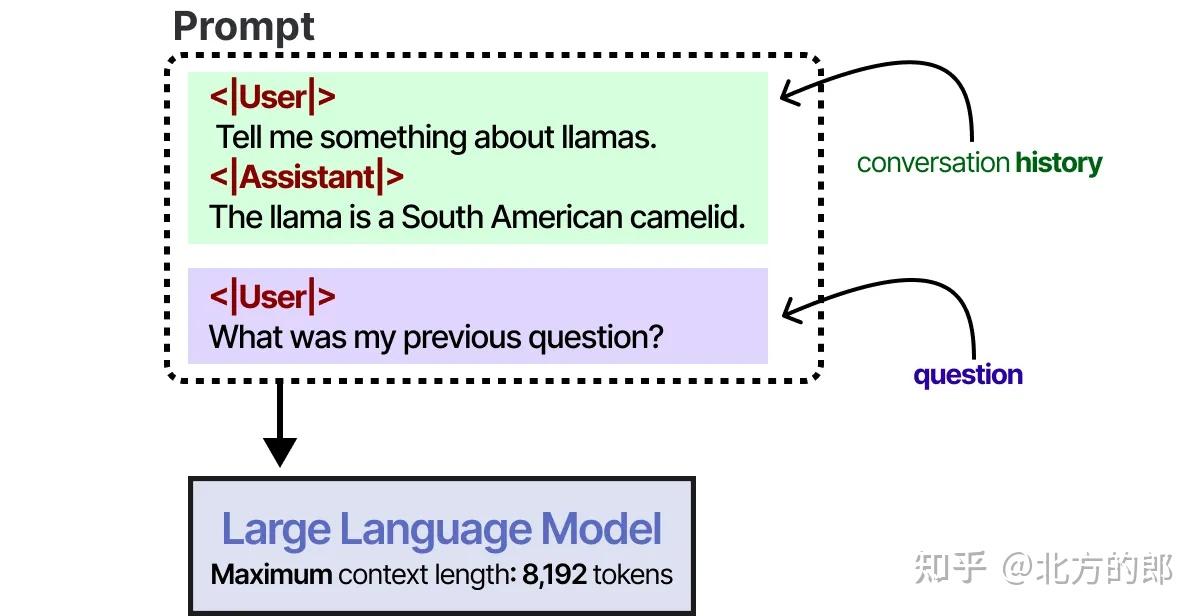
只要对话历史适合LLM的上下文窗口,这种方法就能很好地模拟记忆。然而,与其说是真正记住对话,我们实际上是“告诉”LLM对话内容是什么。
用另一个LLM总结
对于上下文窗口较小的模型,或者当对话历史较长时,我们可以使用另一个LLM来总结迄今为止的对话。
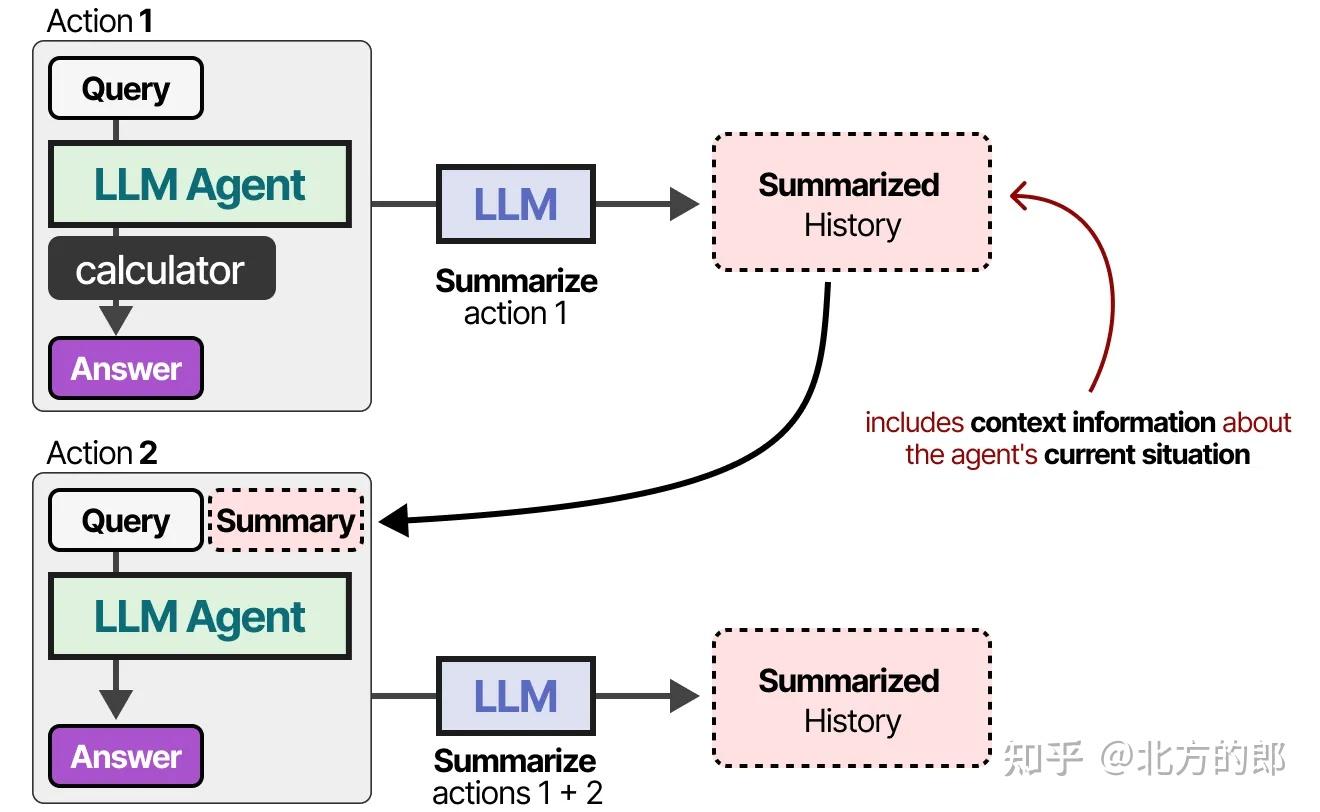
通过持续总结对话,我们可以保持对话内容的精简。它会减少词数,同时仅保留最重要的信息。
长期记忆
用于保留智能体在多个回合、多个任务、多个会话中的知识与经验
LLM智能体还需要跟踪可能多达数十个步骤,而不仅仅是最新的行动。
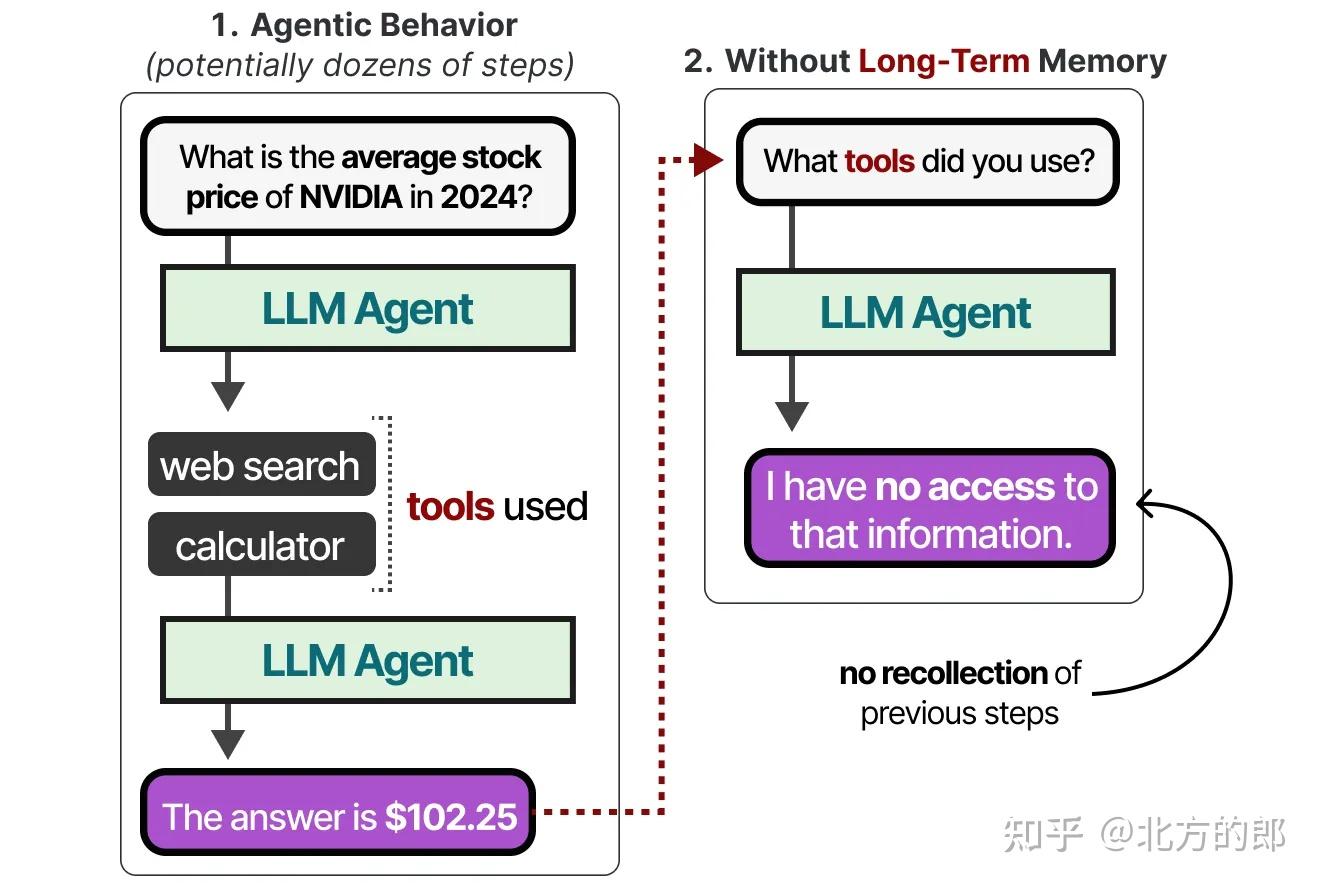
这被称为长期记忆,因为LLM智能体理论上可能需要记住几十甚至数百个步骤。
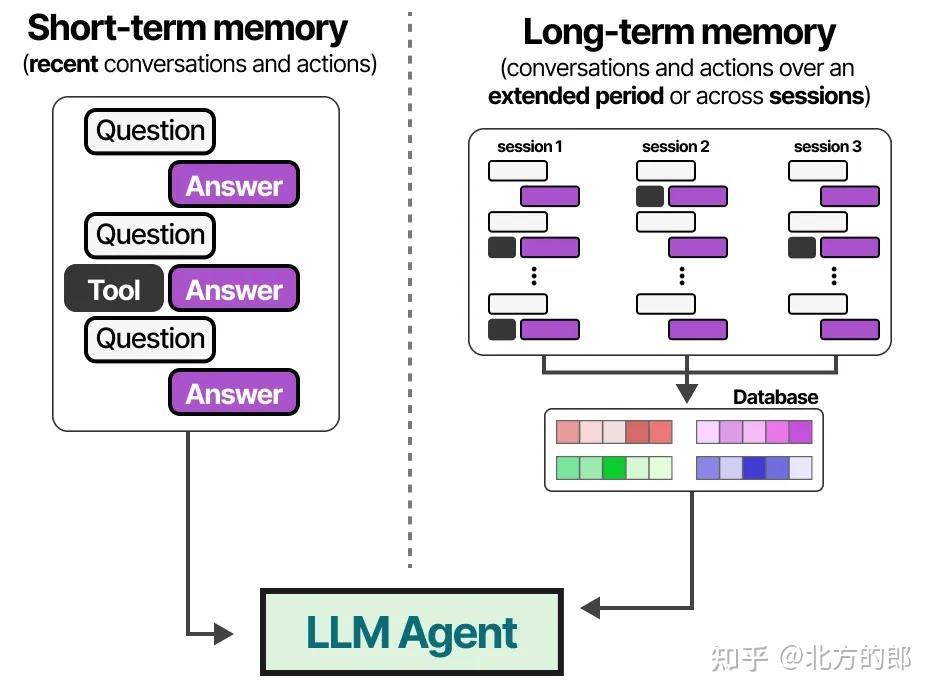
外部向量数据库&RAG
LLM智能体的长期记忆包括智能体过去的行动空间,这些需要在较长时间内保留。
启用长期记忆的常见技术是将所有先前的交互、行动和对话存储在外部向量数据库中。
要构建这样的数据库,首先将对话嵌入到捕捉其含义的数字表示中。
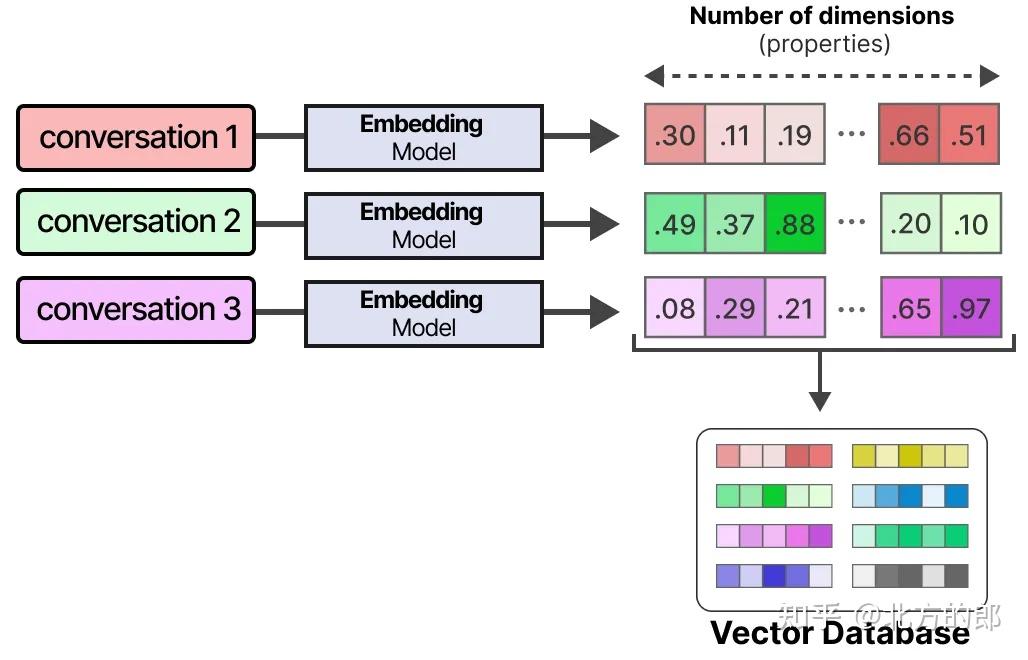
在构建数据库后,我们可以嵌入任何给定的提示,并通过比较提示嵌入与数据库嵌入,找到向量数据库中最相关的信息。
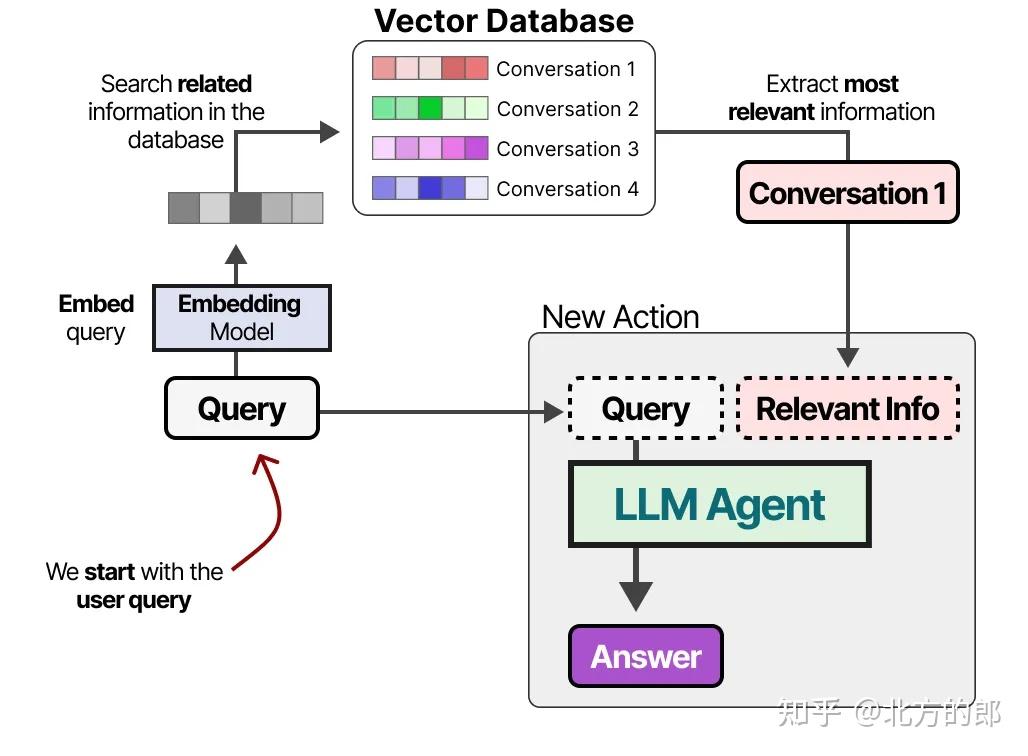
这种方法通常被称为检索增强生成(Retrieval-Augmented Generation, RAG)。
**长期记忆还可以涉及保留不同会话的信息。**例如,你可能希望LLM智能体记住它在之前会话中进行过的任何研究。
不同类型的信息也可以与不同类型的记忆相关联以存储。在心理学中,有许多类型的记忆需要区分,但《语言智能体的认知架构》论文将其中四种与LLM智能体结合起来。

这种区分有助于构建智能体框架。语义记忆(关于世界的事实)可能存储在与工作记忆(当前和最近的情况)不同的数据库中。
工具
工具允许LLM与外部环境(例如数据库)交互,或使用外部应用程序(例如运行自定义代码)。

用途
- 获取数据:访问最新信息(如天气、新闻等)。
- 采取行动:如安排会议、下订单。
工具使用
函数调用
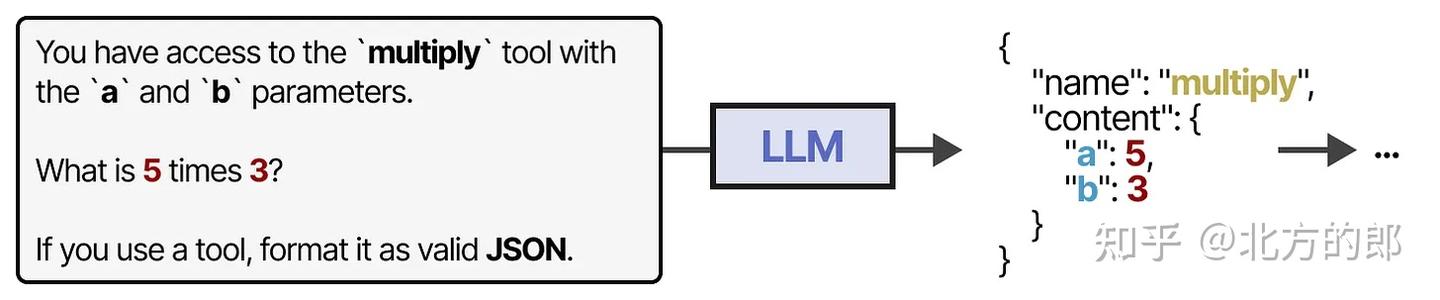
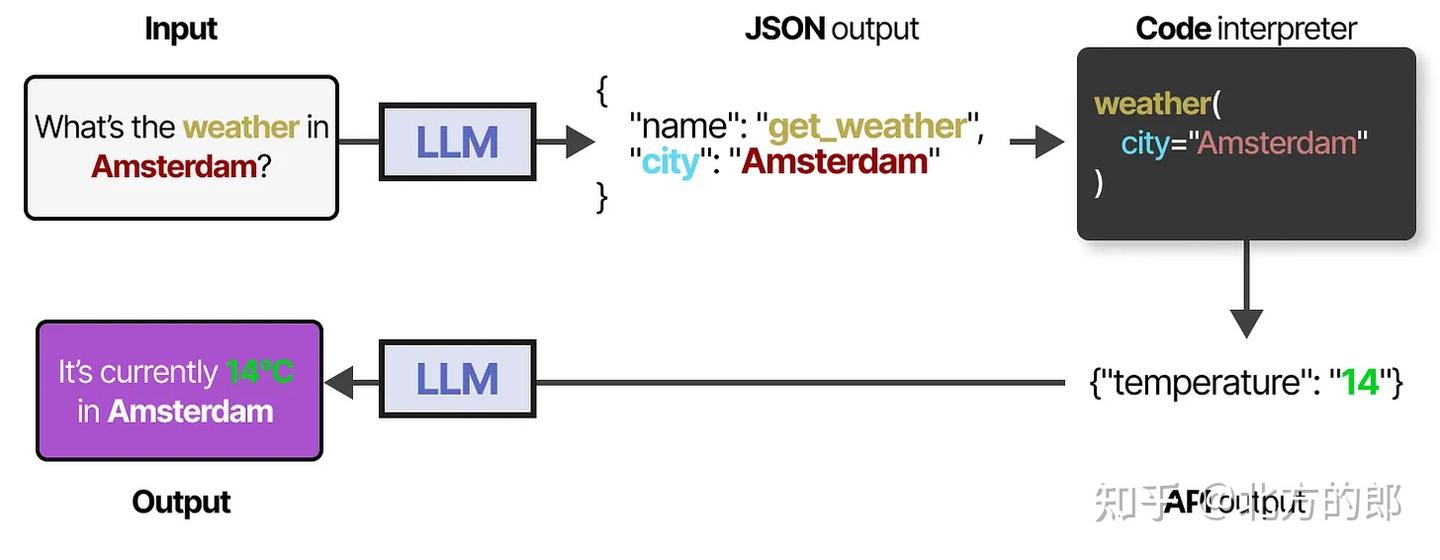
要实际使用工具,**LLM必须生成符合给定工具API的文本。**我们通常期望生成可以格式化为JSON的字符串,以便轻松输入代码解释器。
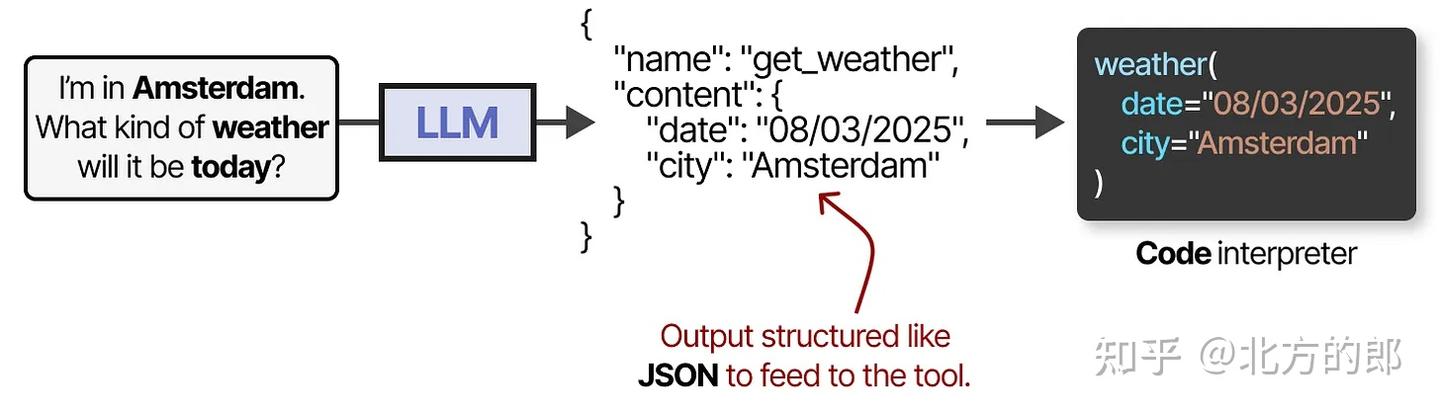
示例:LLM 生成
{"tool": "multiply", "args": {"x": 5, "y": 3}}。**如果正确且详尽地提示,一些LLM可以使用任何工具。**工具使用是当前大多数LLM都具备的能力。
访问工具的更稳定方法是通过微调LLM(稍后会详细介绍!)。
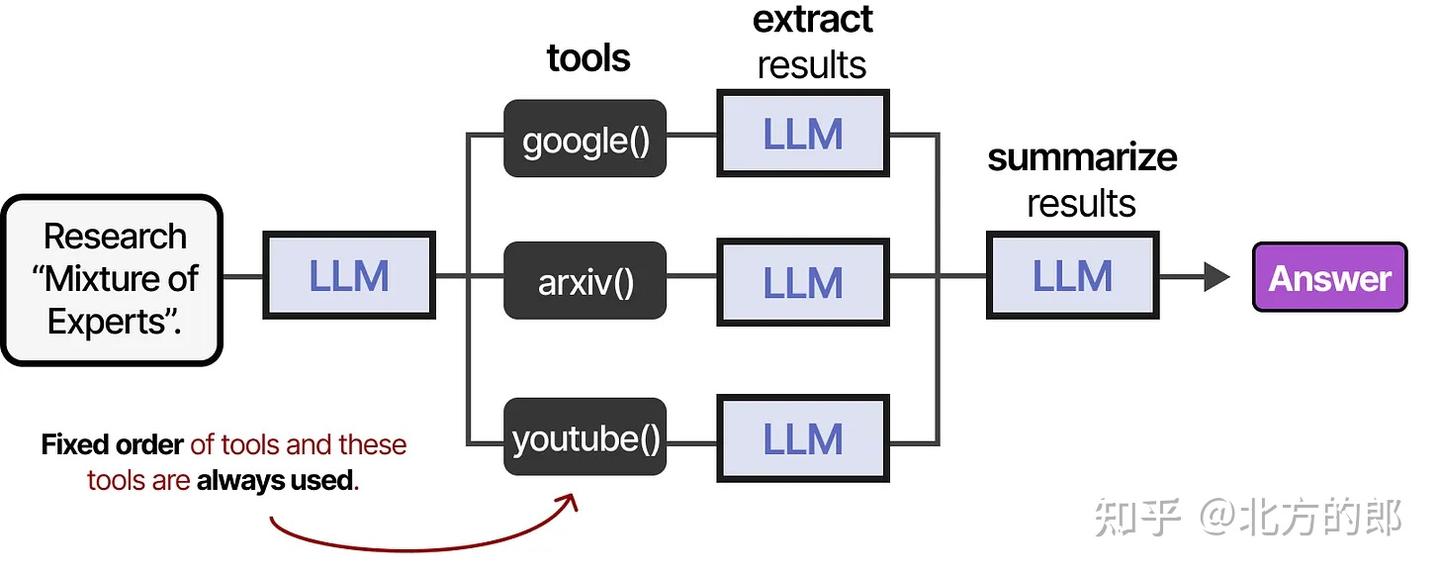
顺序调用
工具可以按固定顺序或由 LLM 自主决定调用顺序。
本质上构成一个Agent 智能体框架:LLM 决策 → 工具执行 → 结果反馈 → 下次决策。
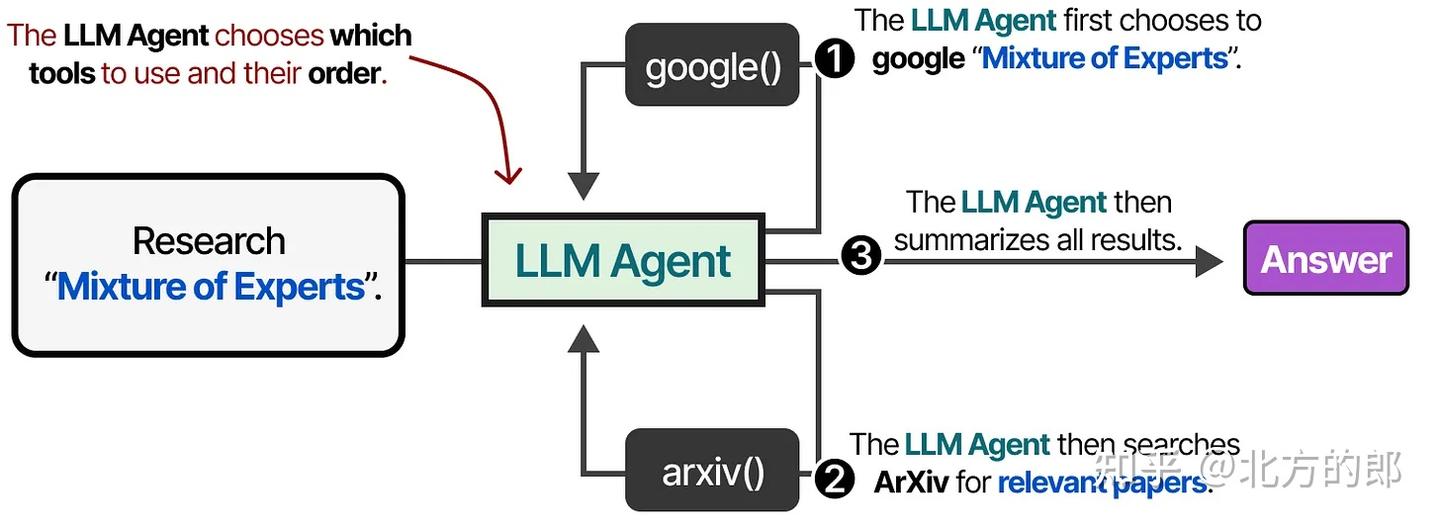
换句话说,中间步骤的输出会反馈给LLM以继续处理。
工具使用的训练范式-Toolformer
目标:让大语言模型(LLM)学会自主判断何时、如何调用工具,增强其处理复杂任务的能力。
方法:
- 用
[ tool_name:input → output ]格式标记训练样本。 - 利用少样本提示生成调用样本,再基于输出质量筛选构建训练集。
意义:无需手动微调代码,只需标注即可训练具备工具使用能力的模型。
关键设计:生成流程详解
| 步骤 | 描述 |
|---|---|
| 输入提示 | 如:“5乘3是多少?” |
| 生成 [ 符号 | 表示即将调用工具 |
| 生成工具名与输入 | 如 calculator: 5*3 |
| 生成 → 符号 | 表示调用结束 |
| 插入输出 | 工具返回的输出如 15 |
| 继续生成文本 | 模型可继续后续自然语言生成 |
工具使用是增强LLM能力并弥补其不足的强大技术。因此,过去几年中关于工具使用和学习的研究迅速激增。
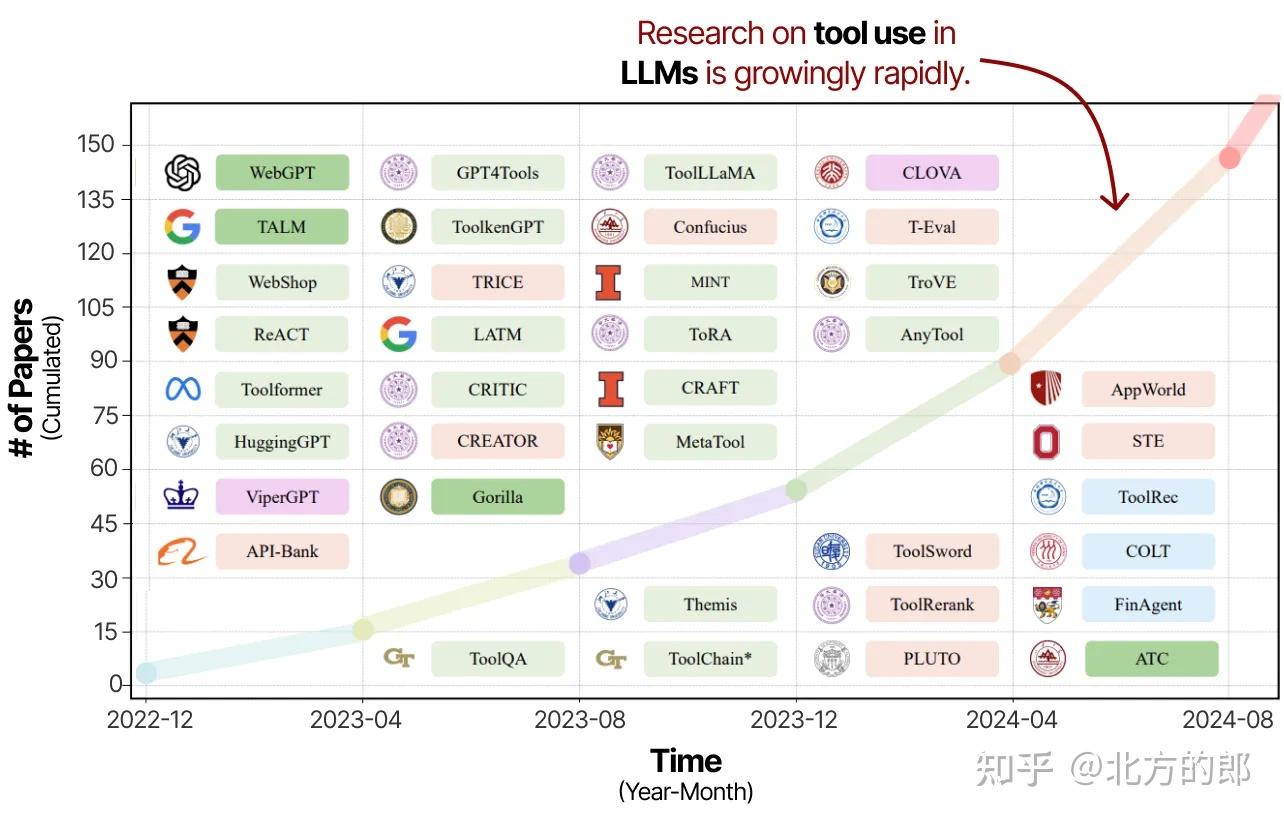
《大语言模型的工具学习:综述》论文的注释和裁剪图片。随着对工具使用的日益关注,(智能体性)LLM预计将变得更加强大。
这些研究不仅涉及提示LLM使用工具,还包括专门训练它们以使用工具。
首批这样做的技术之一被称为Toolformer,这是一个训练来决定调用哪些API以及如何调用的模型。
它使用 [ 和 ] 标记来表示调用工具的开始和结束。例如,当给出提示“5乘3是多少?”时,它会开始生成词,直到遇到 [ 标记。

之后,它会生成词直到遇到 → 标记,表示LLM停止生成词。

然后,工具将被调用,输出将被添加到迄今为止生成的词中。
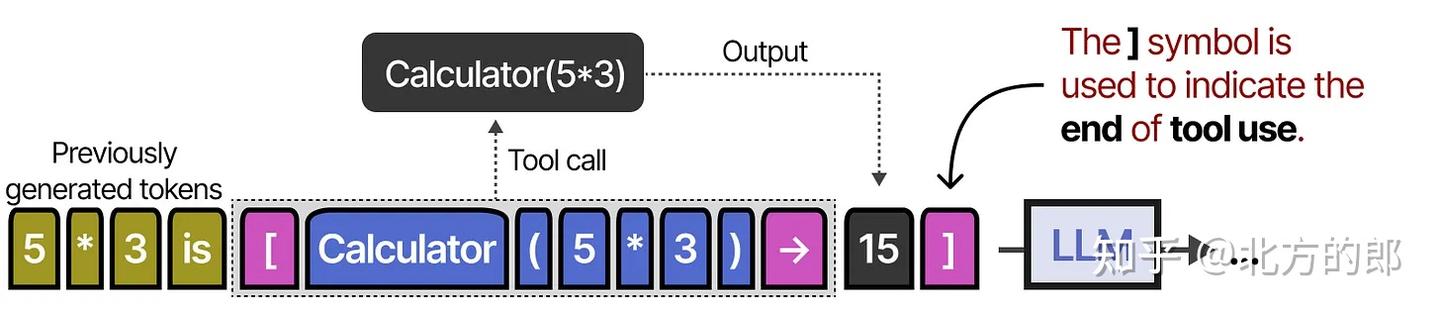
符号表示LLM现在可以继续生成,如果有必要的话。
Toolformer通过精心生成一个包含大量工具使用的数据集来创建这种行为,模型可以在此数据集上进行训练。对于每种工具,手动创建少样本提示,并用于采样使用这些工具的输出。
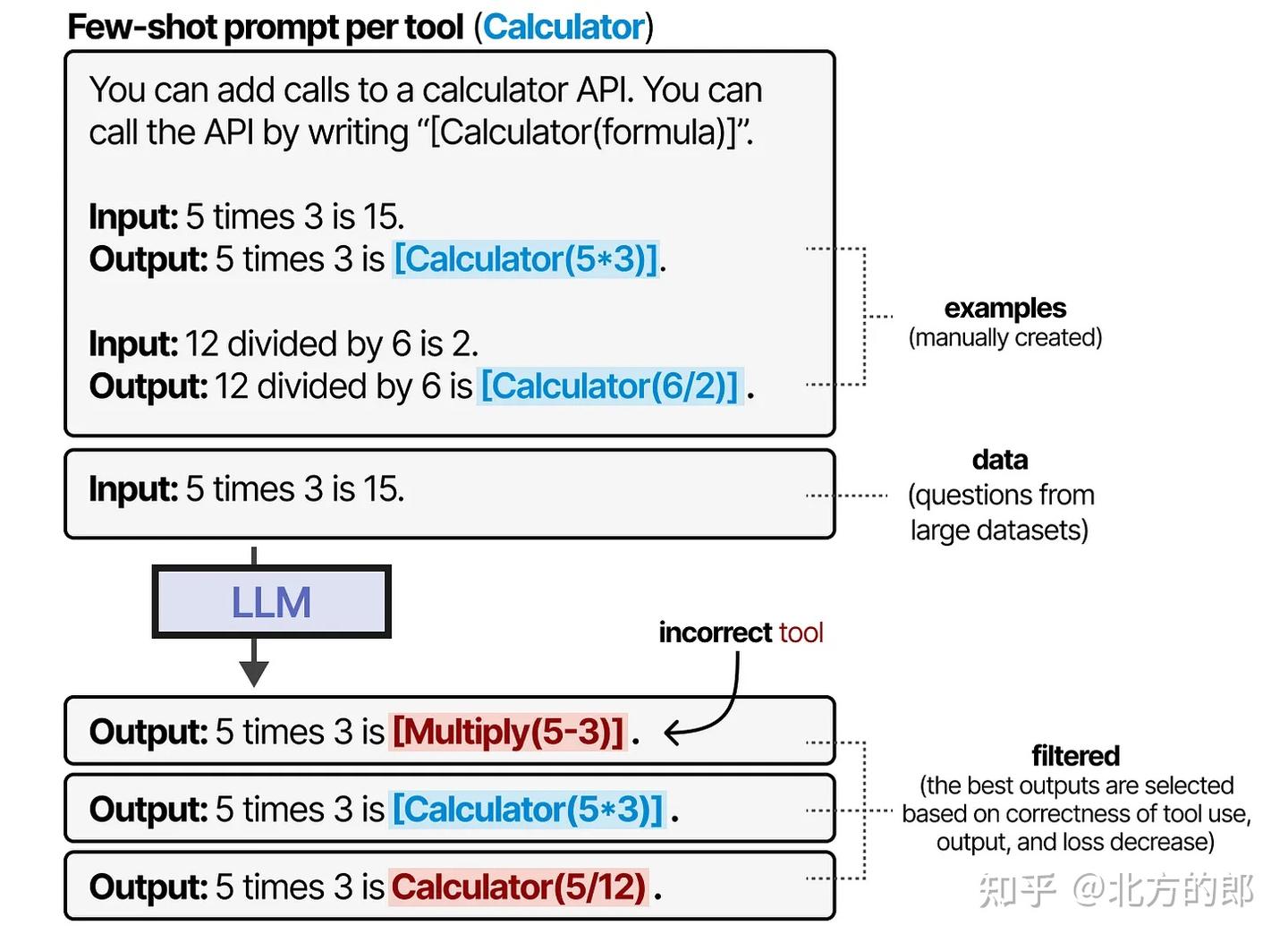
根据工具使用的正确性、输出和损失减少来过滤输出。所得数据集用于训练LLM遵循这种工具使用格式。
自Toolformer发布以来,出现了许多激动人心的新技术,例如可以使用数千种工具的LLM(ToolLLM)或可以轻松检索最相关工具的LLM(Gorilla)。
模型上下文协议(MCP)
痛点
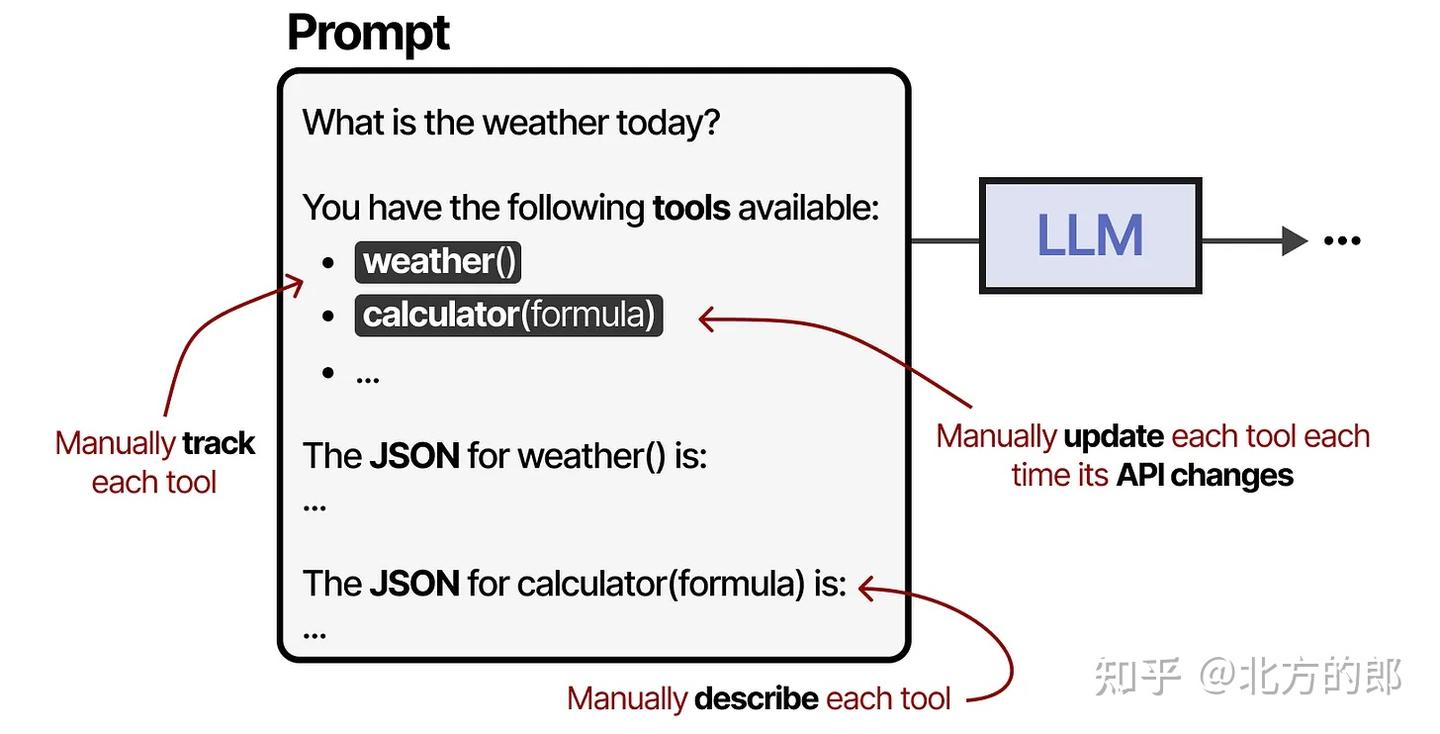
工具是智能体框架的重要组成部分,工具(Tools)是关键组件,允许LLM与世界互动并扩展其能力,但其集成存在三大挑战:
- 手动跟踪并输入给LLM
- 手动描述(包括其预期的JSON模式)
- 每次API更改时手动更新
功能
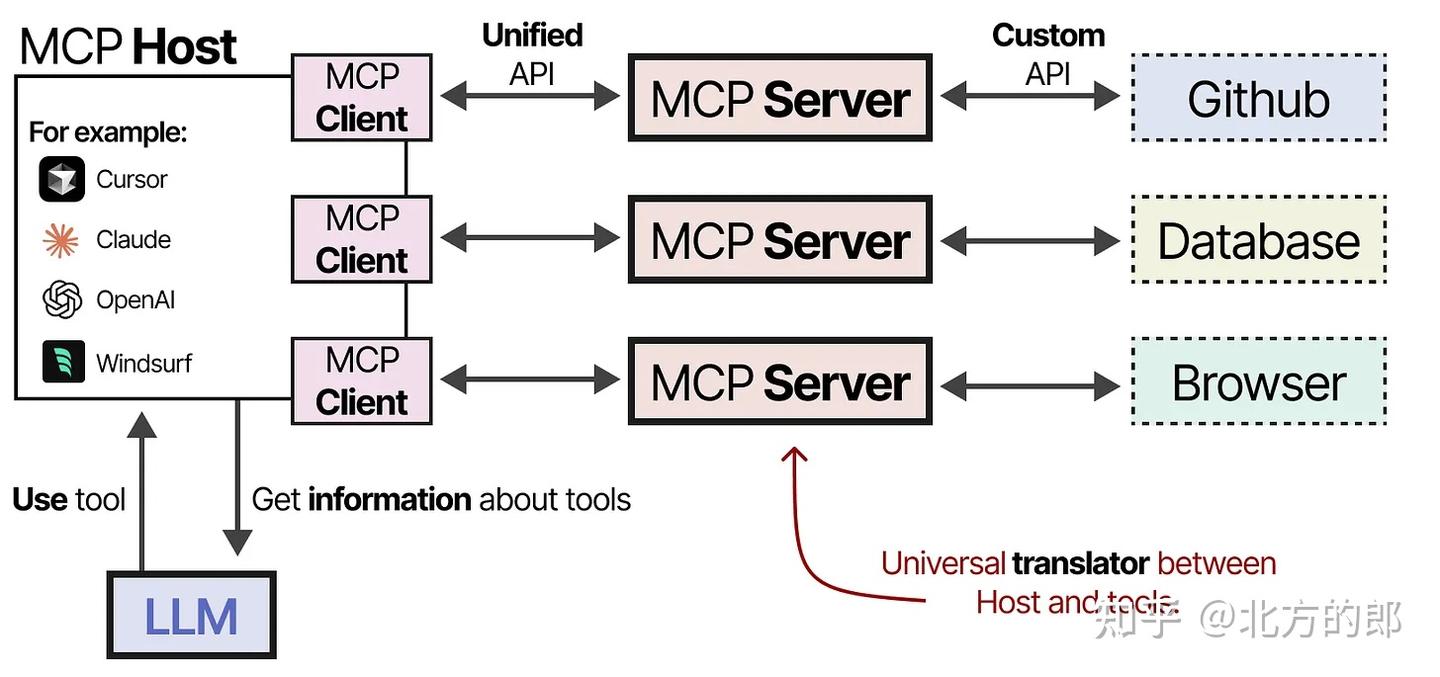
为了使工具更容易在任何给定的智能体框架中实现,Anthropic开发了模型上下文协议(MCP)。通过MCP协议,标准化LLM使用工具的方式,让接入与调用更加通用、模块化和自动化。
组件
它包括三个组件:
- MCP主机 —— 管理连接的LLM应用程序(例如Cursor)
- MCP客户端 —— 与MCP服务器保持1:1连接
- MCP服务器 —— 为LLM提供上下文、工具和能力
流程
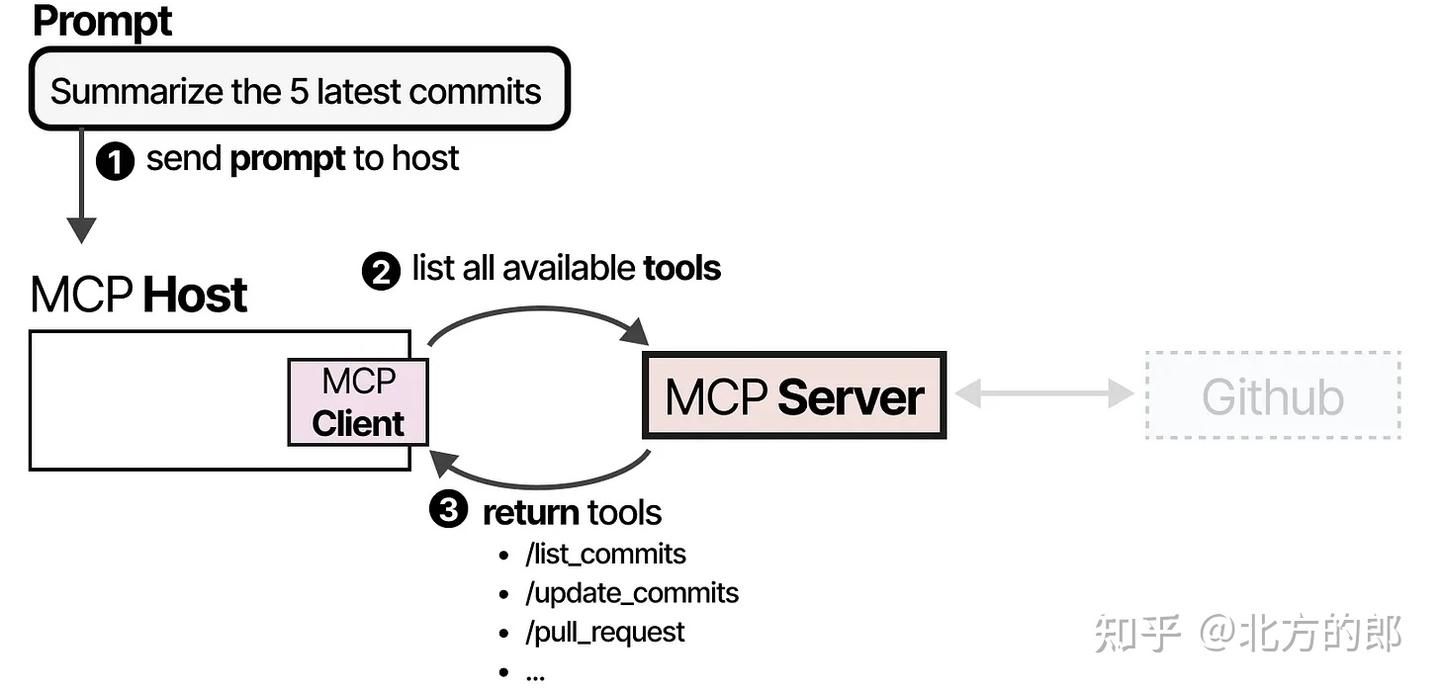
以希望LLM获取 GitHub 最新 5 次提交为例:
MCP主机询问MCP服务器:我有哪些工具可以用? MCP服务器返回工具列表(带调用方法、模式、功能描述等)。示例如下:
1、**工具发现阶段:**MCP主机(与客户端一起)首先会调用MCP服务器,询问有哪些工具可用。:
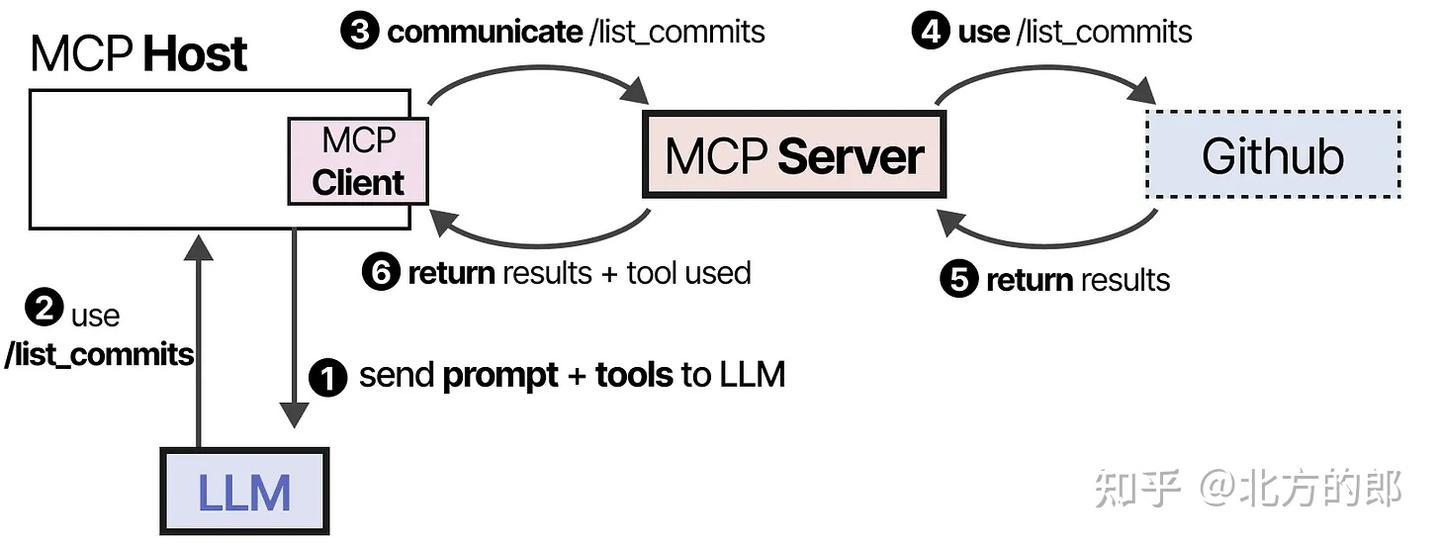
**2、工具调用阶段:**LLM接收到信息后可能会选择使用某个工具。它通过主机向MCP服务器发送请求,然后接收结果,包括使用的工具。
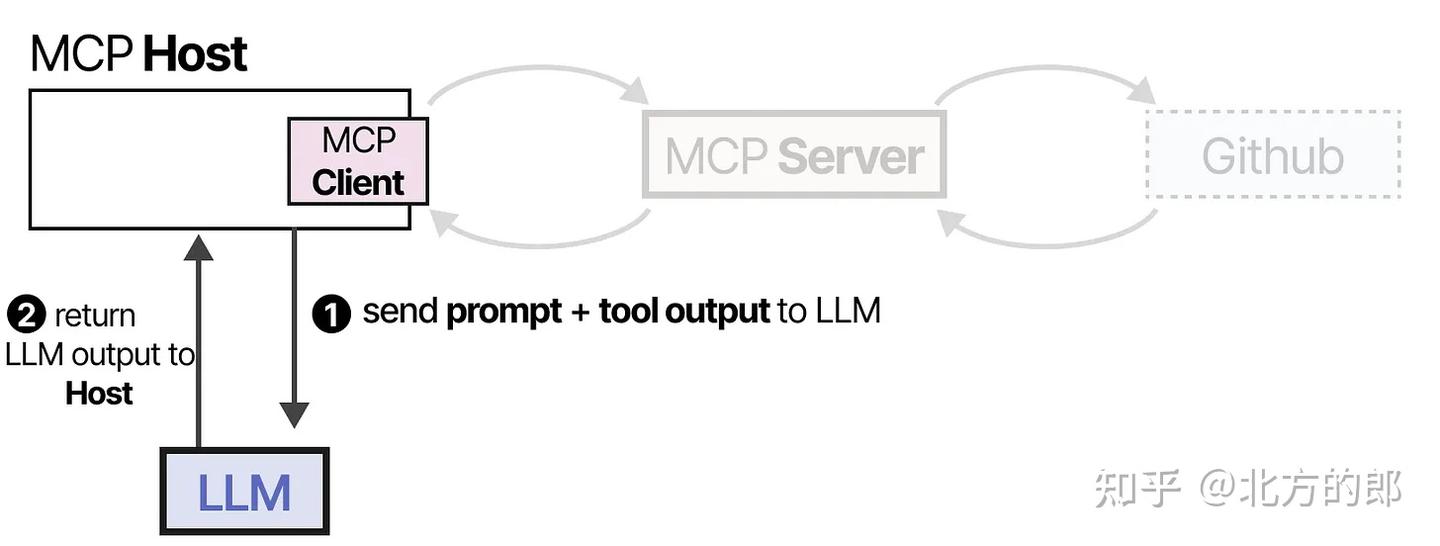
**3、响应整合阶段:**最后,LLM接收结果并可以向用户解析答案。
优势
这个框架通过连接到任何LLM应用程序都可以使用的MCP服务器,使创建工具变得更加容易。因此,当你创建一个与Github交互的MCP服务器时,任何支持MCP的LLM应用程序都可以使用它。
| 优势 | 描述 |
|---|---|
| 统一标准 | 不同服务的工具接口被标准化(如天气、GitHub等 |
| 即插即用 | 工具一旦注册,任意支持MCP的LLM客户端都能用 |
| 自动适配API变化 | 工具定义集中在MCP服务器端,变更无需手动通知LLM |
| 提高工具复用性 | 同一工具可被多个LLM共享,降低重复开发成本 |
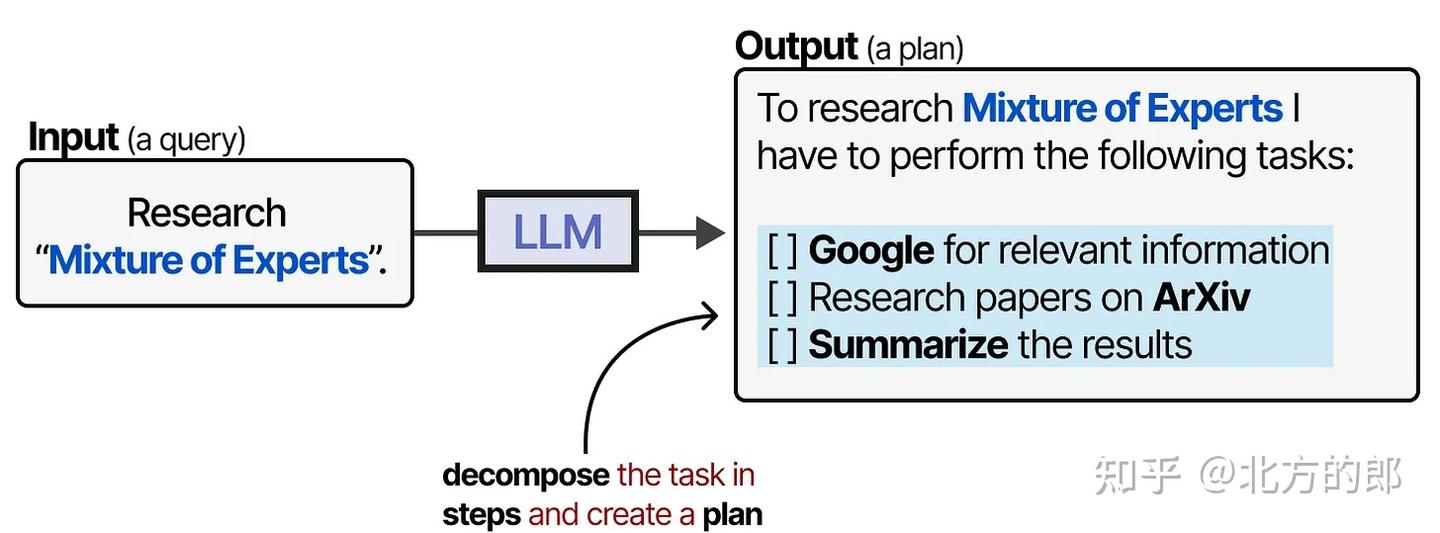
规划
意义
- LLM 使用工具(如插件、API)时,需要判断何时调用哪个工具。
- 智能体要完成复杂任务,必须能将其拆解成可操作的步骤。
- 这类任务分解能力正是“规划”的核心。
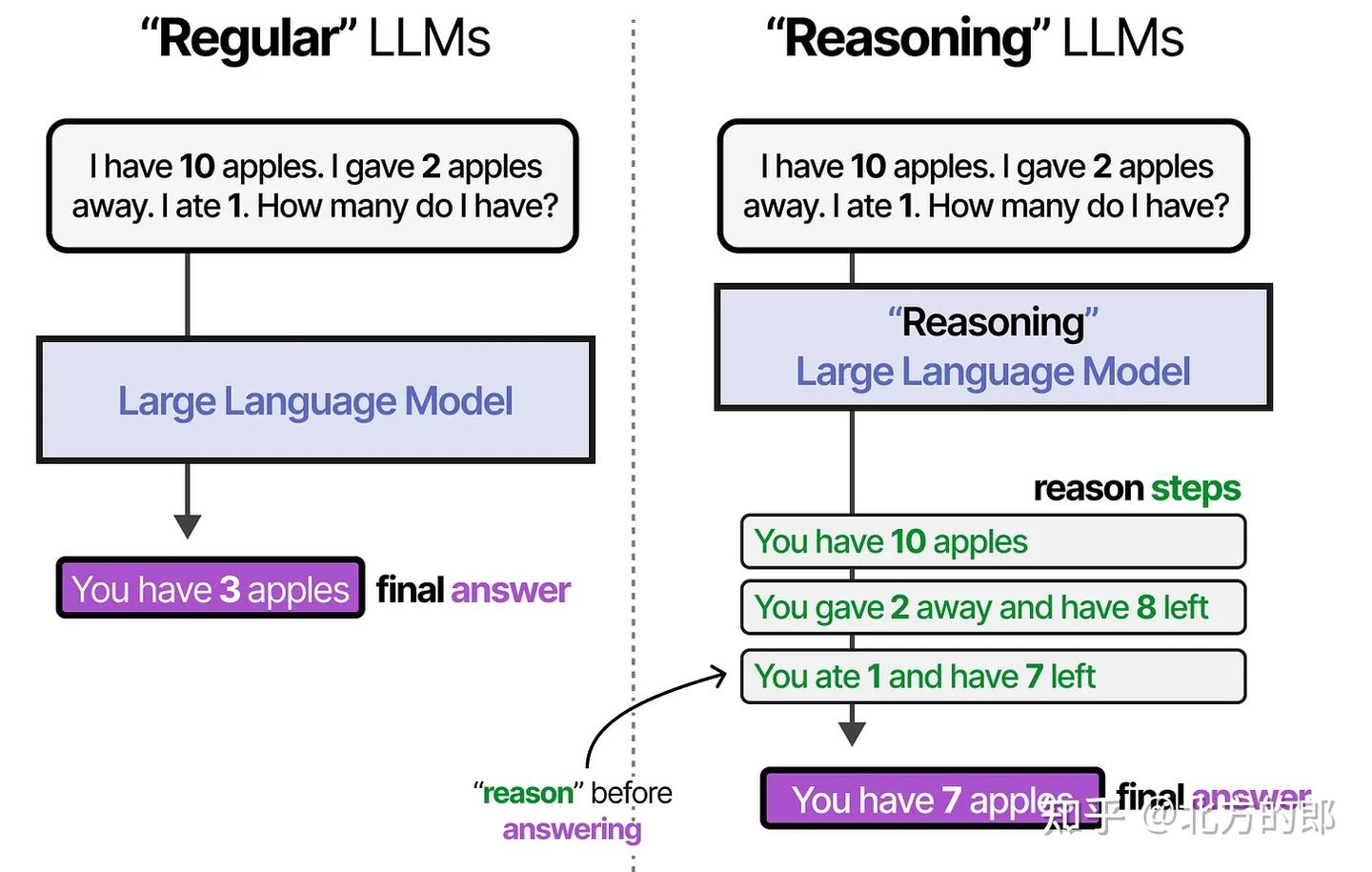
推理
推理 ≈ 在行动前“思考”
推理是规划的基础。
推理让 LLM 不只是直接回答问题,而是层层拆解、逐步接近目标。“推理”LLM是那些在回答问题之前倾向于“思考”的模型。
推理的激活/启用方式:
- 微调(Fine-tuning)
- 提示工程(Prompt Engineering)
微调
微调的意义如下:
1、从模型的训练过程来理解:一般来说分成三个阶段,预训练 Pre-training,有监督微调 Supervised finetuning、对齐 Alignment。其中后两个阶段都是微调的阶段。
- 预训练阶段,模型会学习来自海量、无标注文本数据集的知识。
- 然后使用有监督微调的方式来细化模型,以便后期在推理的过程中更好地遵守特定指令。
- 最后使用对齐技术使 LLMsLLMs 可以更有用且更安全地响应用户的提示 Prompt。
**2、让模型具备特定能力:**预训练的模型只是具备通用能力,要处理某个特定领域的问题,必须要灌给这个领域的知识,让模型学习到新的知识。
**3、从成本降低视角:**从趋势来看,LLM的参数量只会越来越大。这对AI集群和算力的消耗就会更多,成本不断提升。所以需要允许少量地重新调整预训练大模型的权重参数,有助于降低训练大模型的复杂性,降低重新进行训练的成本。
通过模型的微调,可以达到如下目的:
**1、定制化模型:**通过微调大型,可以根据用户自身的具体需求定制模型,从而提高准确性和性能。
**2、提高资源利用率:**通过减少从头开始构建新模型的方式进行预训练,从而来节省时间、算力资源和其他带来的成本。
**3、性能提升:**微调的过程,可以使用用户的独特数据集,来增强预训练模型的性能。
**4、数据优化:**可以充分利用客户的数据,调整大模型以更好地适应用特定数据场景,甚至在需要时合并新数据。
提示工程&“思维链COT”
通过提供 思考步骤的示例,让 LLM 学会如何推理。
分为:
少样本提示(提供示例)这种提供思维过程示例的方法被称为“思维链”(Chain-of-Thought),它能够实现更复杂的推理行为。
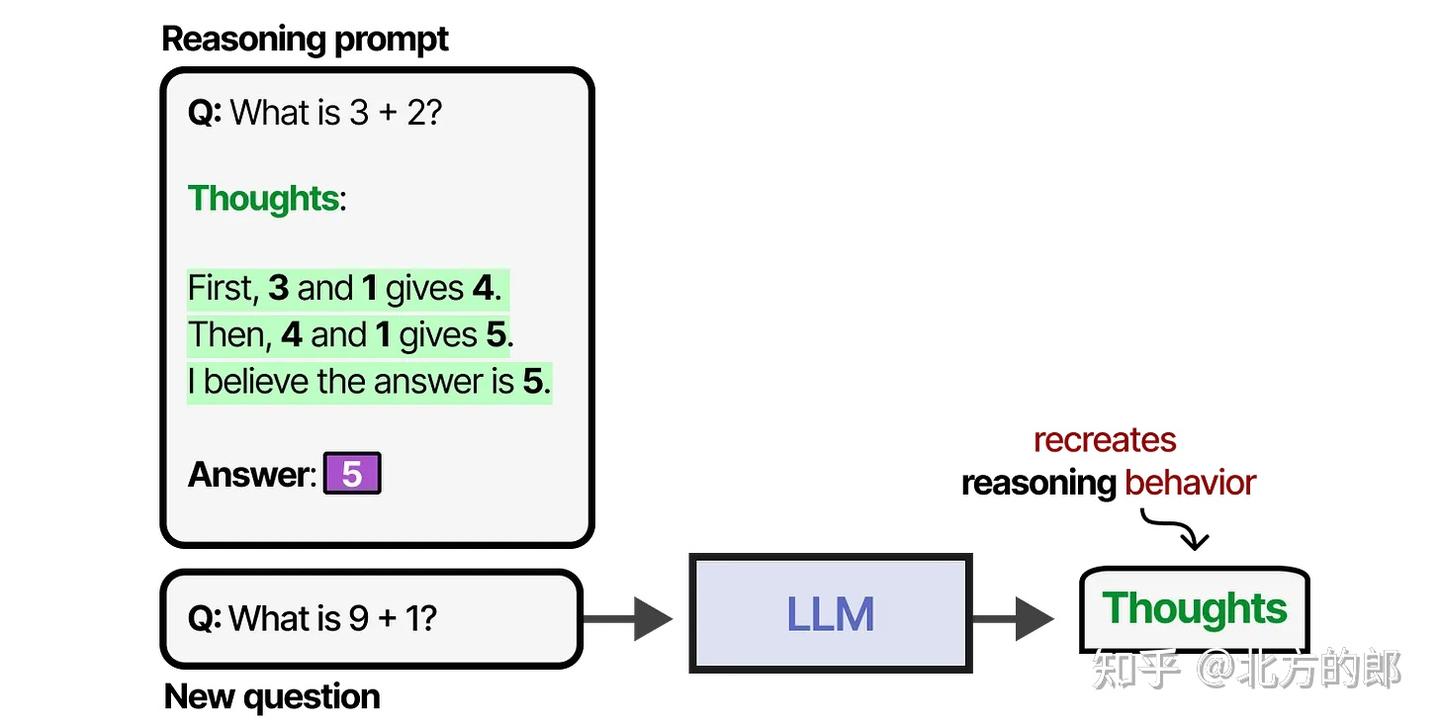
零样本提示(如:“让我们一步步思考”)
思维链也可以在没有任何示例的情况下启用(零样本提示),只需简单地说“让我们一步步思考”。
在训练LLM时,我们可以给它提供足够多的包含类似思维示例的数据集,或者让LLM发现自己的思考过程。

一个很好的例子是DeepSeek-R1,它使用奖励来指导思考过程的使用。
推理与行动
现有痛点
在大多数 LLM 应用中:
- 思维链(Chain-of-Thought, CoT) 主要用于推理,帮助模型一步步解决复杂问题;
- 工具调用等系统主要用于行动,即模型与外部环境的交互。
但单独的推理或行动并不能实现完整、灵活的智能体行为。
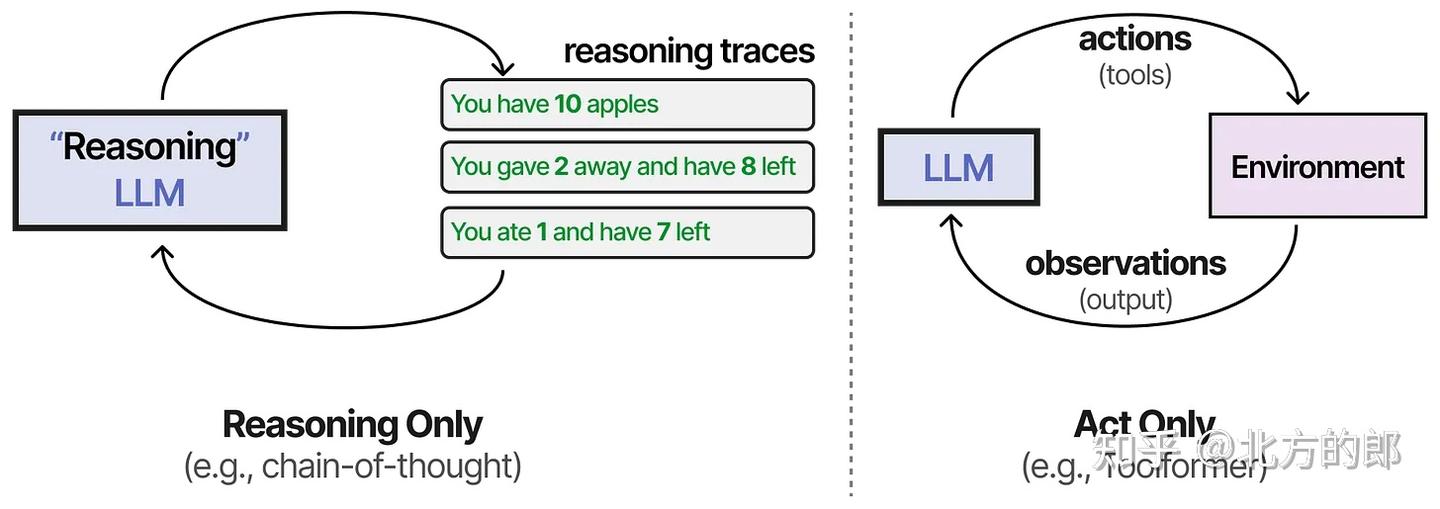
ReAct
首批结合这两个过程的技术之一被称为ReAct(推理与行动)。 ReAct(Reason + Act)框架通过精心设计的提示,使LLM能在一个统一流程中完成:
- 思考(Thought) 模型对当前问题或环境进行推理,得出下一步计划。
- 行动(Action) 执行具体操作,如调用工具、搜索、查询等。
- 观察(Observation) 获取并理解行动结果,为下一轮推理提供依据。
LLM 在“思考 → 行动 → 观察”循环中不断调整决策,直到任务完成。
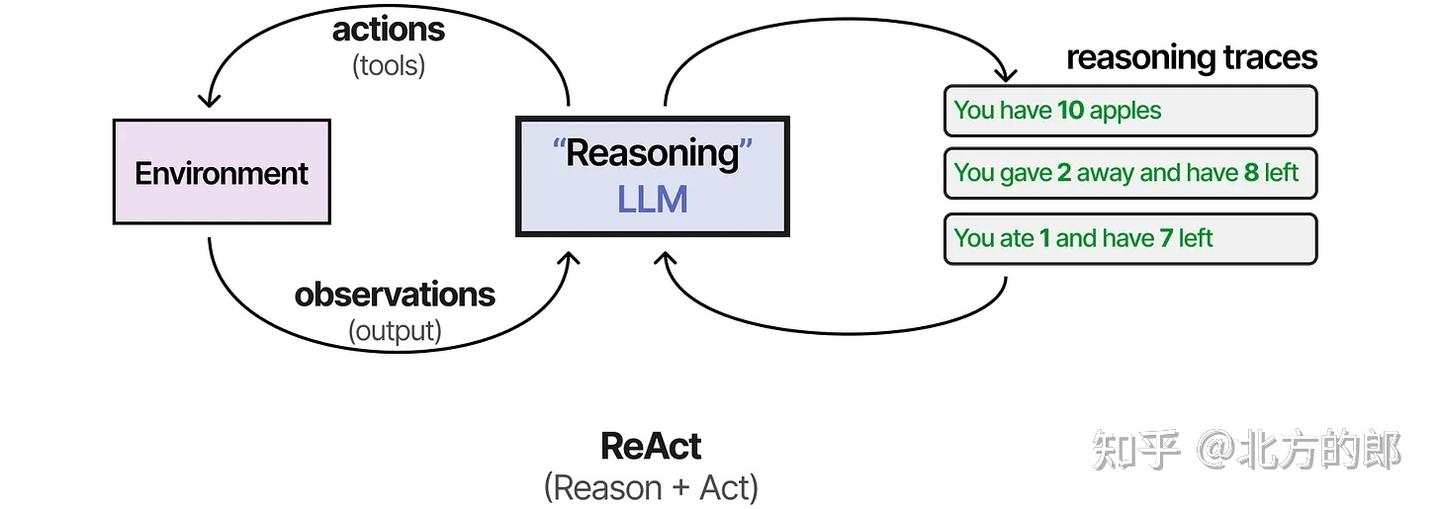
提示示例
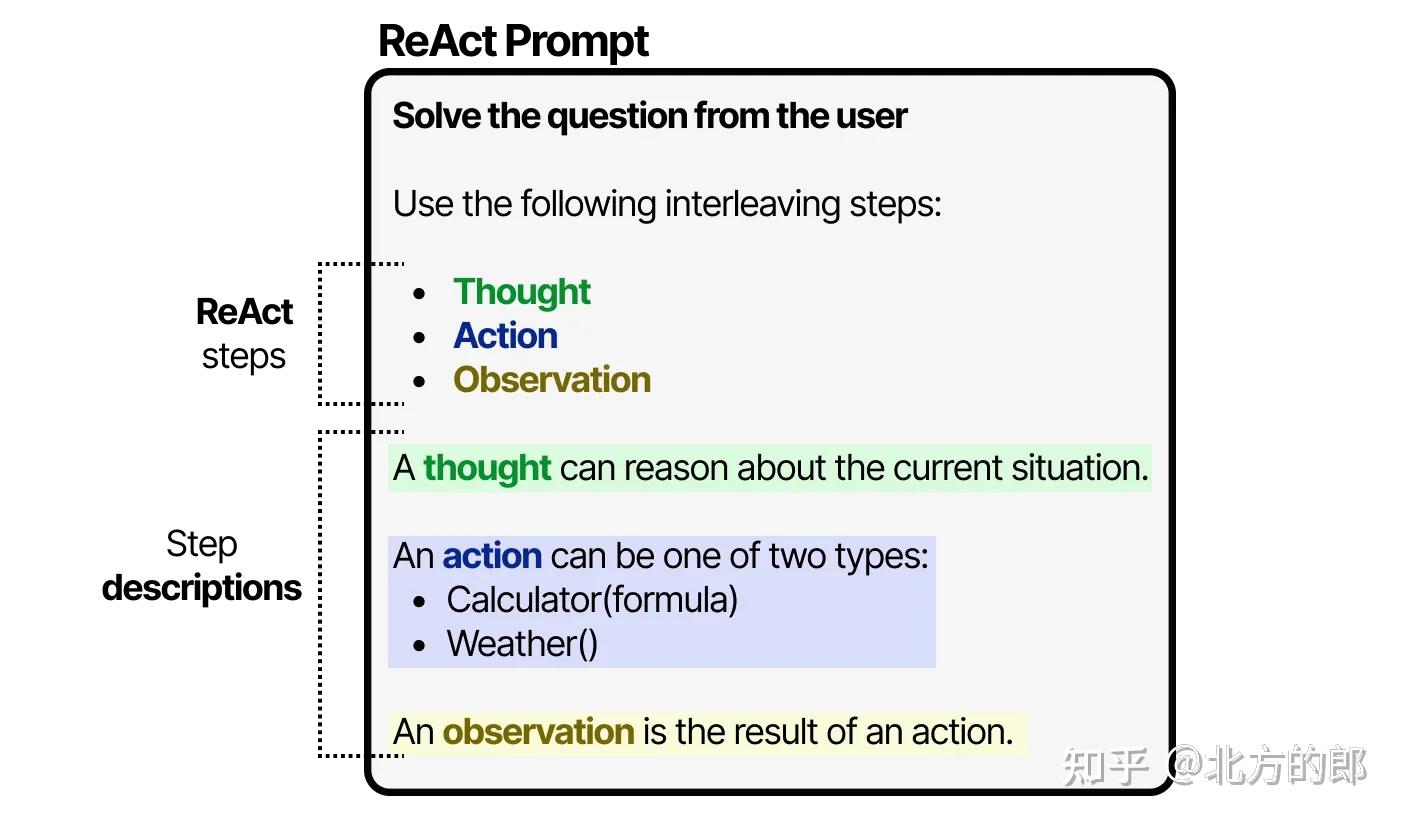
LLM使用这个提示(可以用作系统提示)来引导其行为,以思考、行动和观察的循环方式工作。
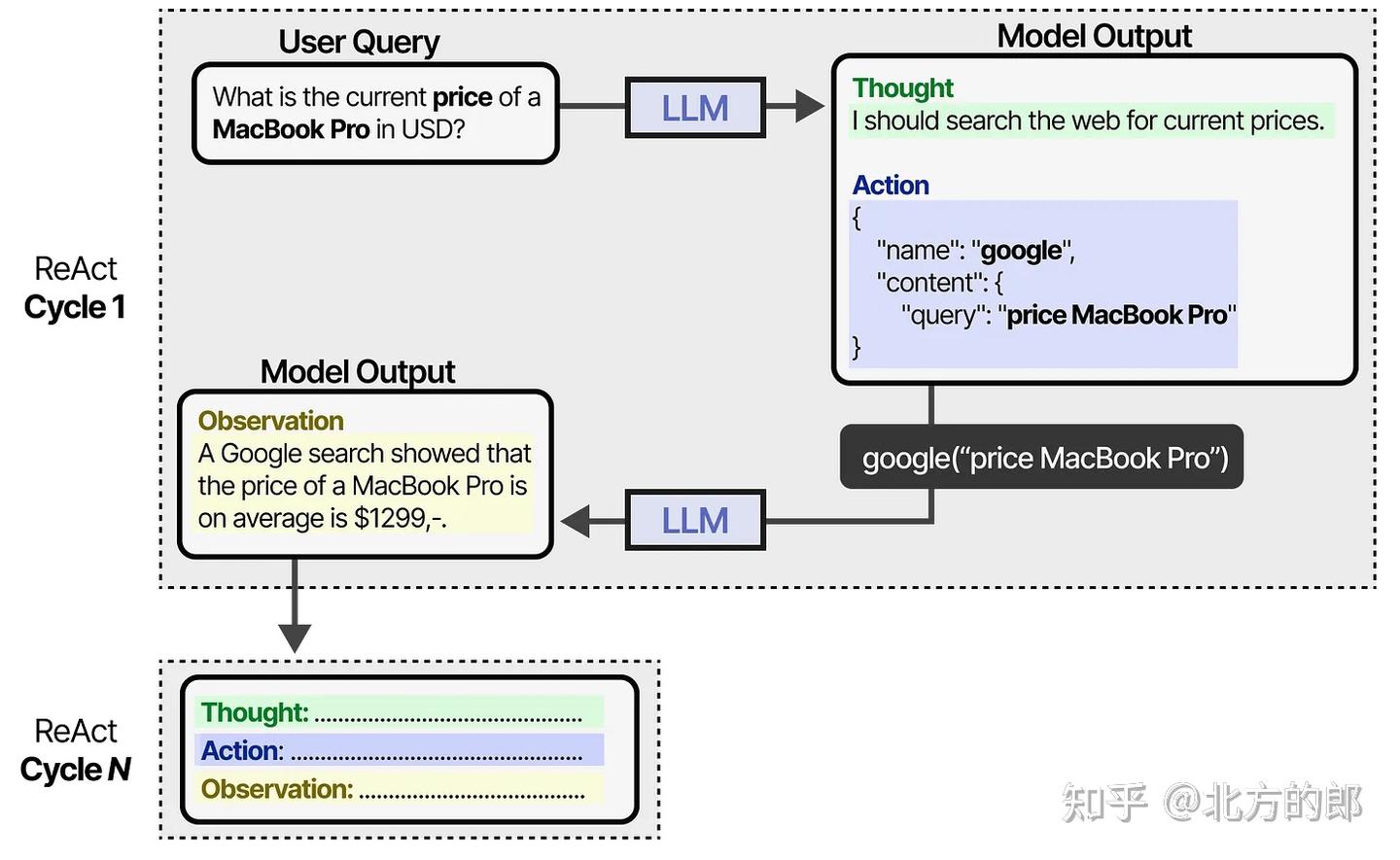
它会持续这种行为,直到某个行动指定返回结果为止。通过迭代思考和观察,LLM可以规划行动,观察其输出,并相应调整。
优势
- 动态规划:不像传统系统那样固定步骤,LLM可根据观察结果灵活调整行动。
- 增强自主性:使模型具备一定“自主决策”能力。
- 工具结合自然:支持 LLM在自然语言推理中灵活调用外部资源。
反思
痛点
尽管 ReAct 强调 “推理+行动” 的循环,但它仍存在一个显著缺陷:
❌ 无法从失败中学习 —— 每次任务都是“从头开始”,无“记忆”与“反思”。
定义
这个过程在ReAct中缺失,而Reflexion填补了这一空白。Reflexion是一种使用口头强化帮助智能体从先前失败中学习的技术。
三种角色
该方法假设三种LLM角色:
- 行动者 —— 根据状态观察选择并执行行动。我们可以使用诸如思维链或ReAct等方法。
- 评估者 —— 对行动者产生的输出评分。
- 自我反思 —— 反思行动者采取的行动和评估者生成的分数。
Reflexion 添加记忆模块来跟踪行动(短期)和自我反思(长期),帮助智能体从错误中学习并识别改进的行动。
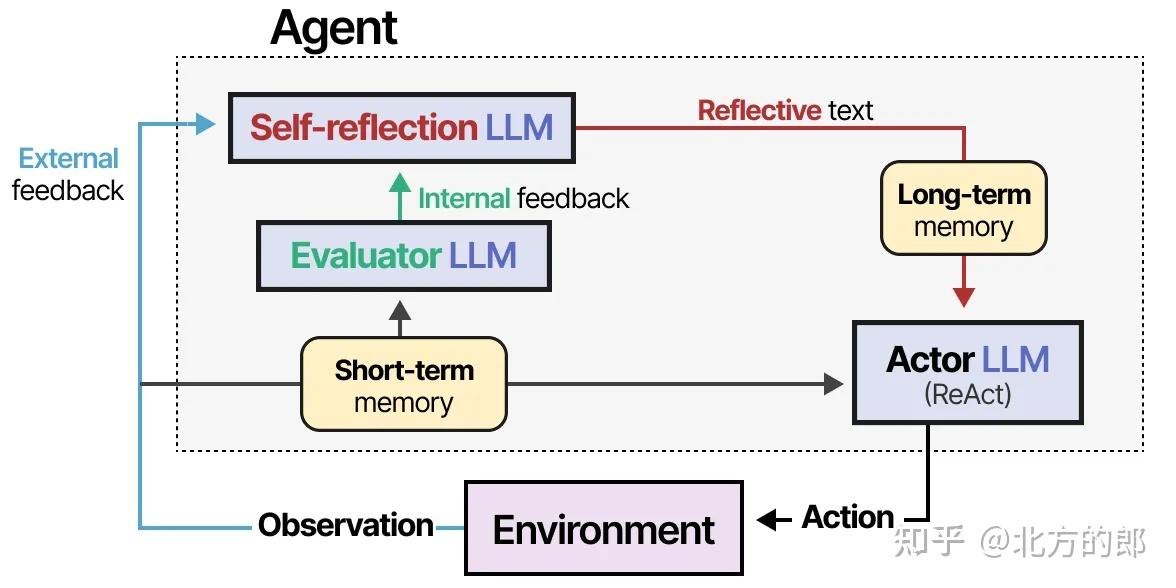
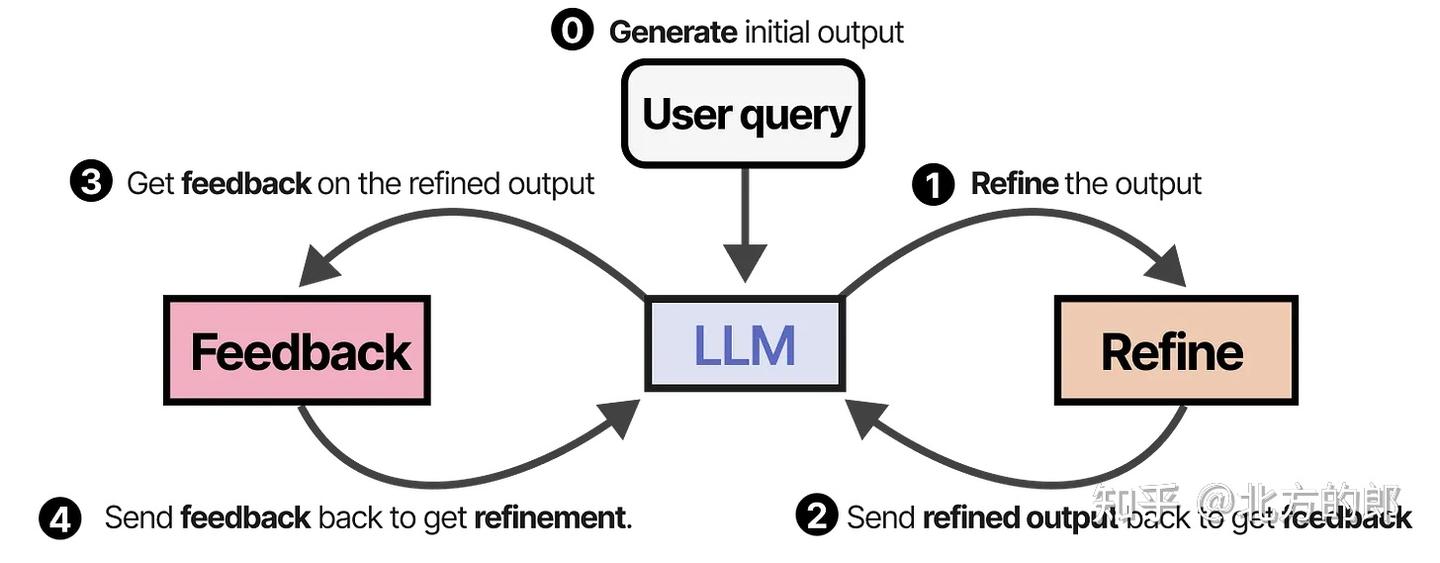
SELF-REFINE
SELF-REFINE 是一种更精炼的迭代优化方法,特点如下:
- 同一个 LLM 充当多个角色:
- 生成初始输出
- 自我评价输出
- 基于反馈进行优化
- 多轮循环迭代,直到满足质量标准或达到预设轮数。
同一个LLM负责生成初始输出、优化输出和反馈。
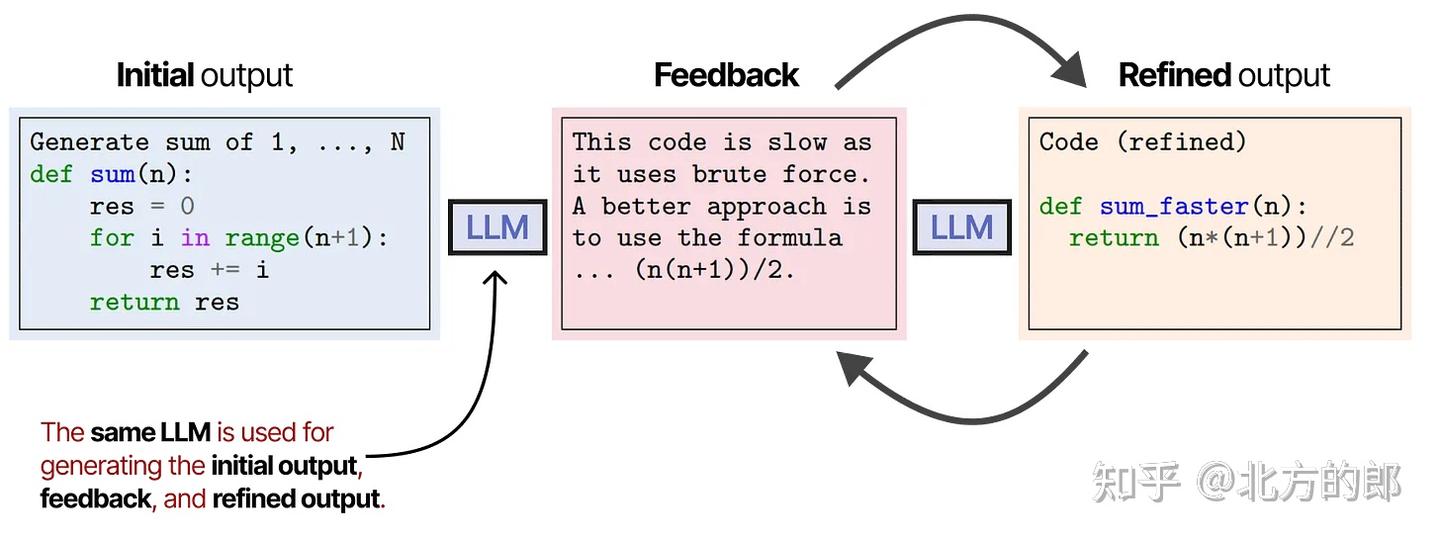
有趣的是,这种自我反思行为(Reflexion和SELF-REFINE)与强化学习非常相似,其中根据输出的质量给予奖励。
| 特性 | Reflexion | SELF-REFINE |
|---|---|---|
| 自我反馈能力 | ✅ 强 | ✅ 强 |
| 多角色支持 | ✅(行动者/评估者/反思者) | ❌(全部由LLM一人扮演) |
| 是否支持多轮优化 | ✅ | ✅ |
| 是否结合记忆模块 | ✅ 支持短期+长期记忆 | ❌(偏静态) |
| 类似强化学习中的“奖励信号” | ✅ | ✅ |
多智能体
定义与解决的问题
在传统的单一智能体系统中,存在以下挑战:工具过多可能使选择复杂化,上下文变得过于复杂,任务可能需要专业化。
- 工具冗杂:太多工具令决策路径变得复杂
- 上下文超载:长上下文导致理解与处理困难
- 通才能力不足:一些任务需要高度专业化的知识与处理方式
相反,我们可以转向多智能体框架,其中多个智能体(每个都有工具、记忆和规划能力)相互交互并与环境交互:
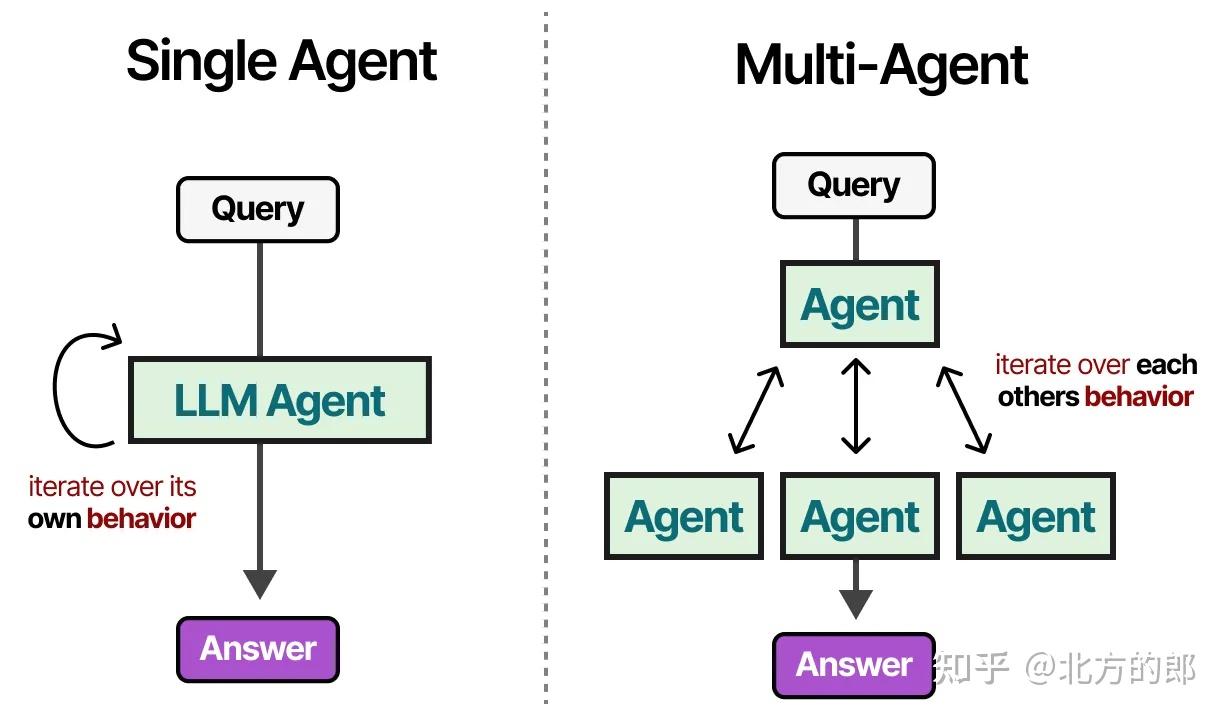
构成
这些多智能体系统通常由专业化的智能体组成,每个智能体配备自己的工具集,并由一个监督者监督。监督者管理智能体之间的通信,并可以将特定任务分配给专业化智能体。每个智能体可能拥有不同类型的工具,但也可能有不同的记忆系统。
多智能体系统通常包括以下组成:
- 专业化智能体
- 每个智能体负责特定任务(如写作、检索、规划)
- 配备独立的工具集、记忆系统与决策逻辑
- 监督者
- 管理任务的分配与智能体之间的通信
- 决定哪个智能体处理哪个子任务
- 负责协调与融合输出结果
- 工具与记忆系统
- 智能体可以拥有不同的工具(API、搜索器、计算器等)
- 记忆系统也可细分为短期记忆、长期记忆或共享记忆库
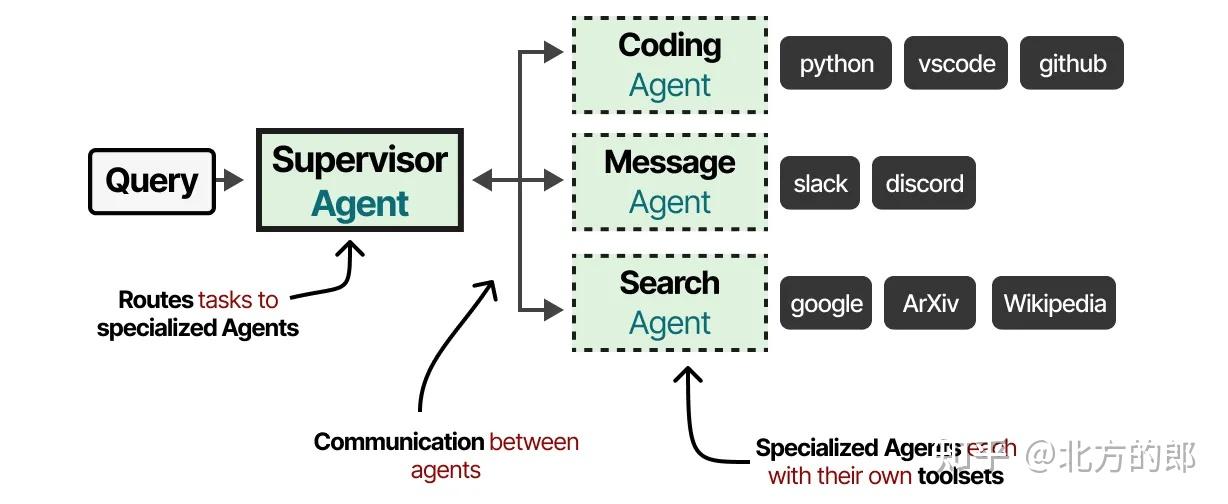
核心问题
- 智能体初始化 —— 如何创建个体(专业化)智能体?
- 智能体编排 —— 如何协调所有智能体?
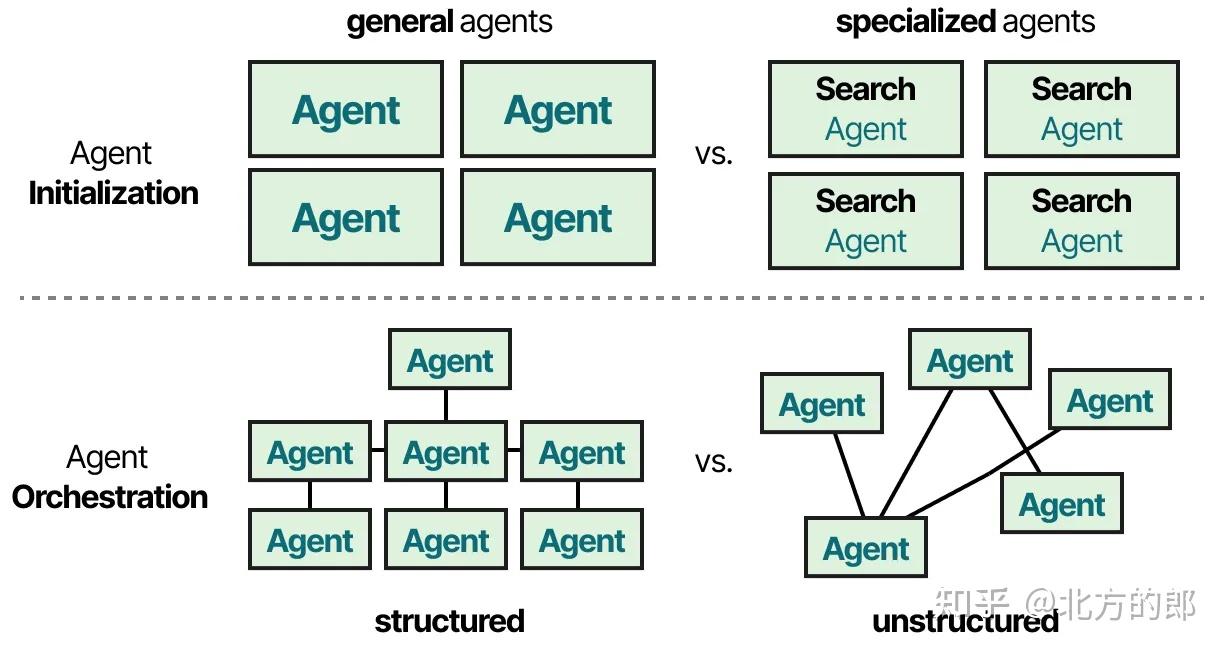
多智能体分类
两种最流行的多智能体架构是
- 协调者——个体智能体由一个中央协调者智能体协调。协调者控制所有的通信流和任务委托,根据当前上下文和任务要求决定调用哪个智能体。
- 集群——智能体根据其专业性动态地将控制权相互移交。系统会记住上一个活跃的智能体,确保在后续交互中与该智能体恢复对话。
协调者

集群

人类行为的交互性模拟
可以说最具影响力且非常酷的多智能体论文之一是《生成智能体:人类行为的交互式模拟》。
在该论文中,他们创建了模拟可信人类行为的计算软件智能体,称之为生成智能体(Generative Agents)。
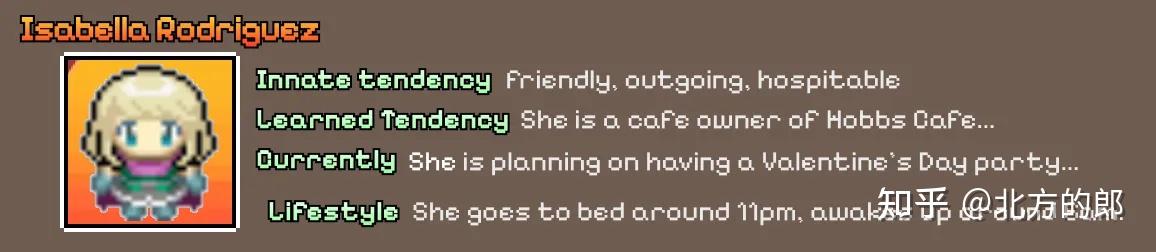
每个生成智能体的配置文件使它们以独特的方式行事,并有助于创造更有趣和动态的行为。
每个智能体通过三个模块(记忆、规划和反思)初始化,这与我们之前看到的ReAct和Reflexion的核心组件非常相似。
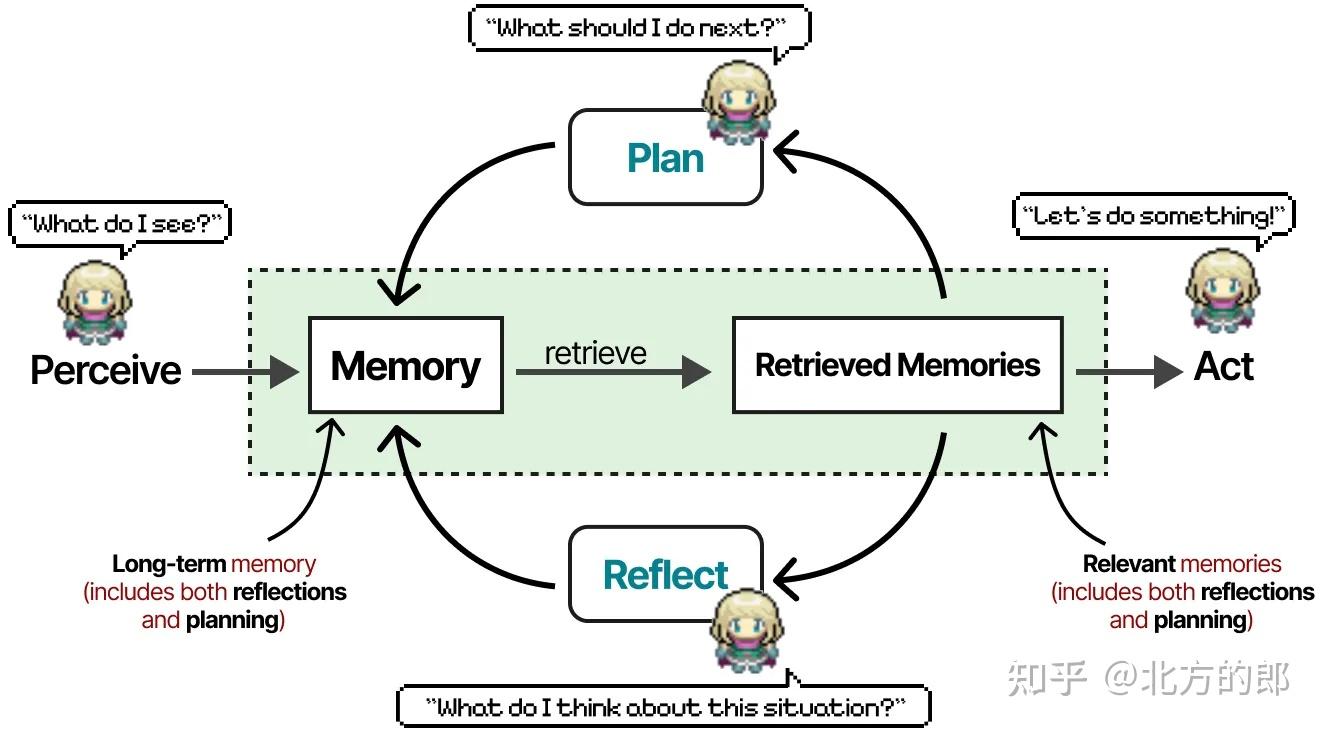
记忆模块是该框架中最关键的组件之一。它存储规划和反思行为,以及迄今为止的所有事件。
对于任何给定的下一步或问题,会检索记忆并根据其最近性、重要性和相关性评分。得分最高的记忆会与智能体共享。
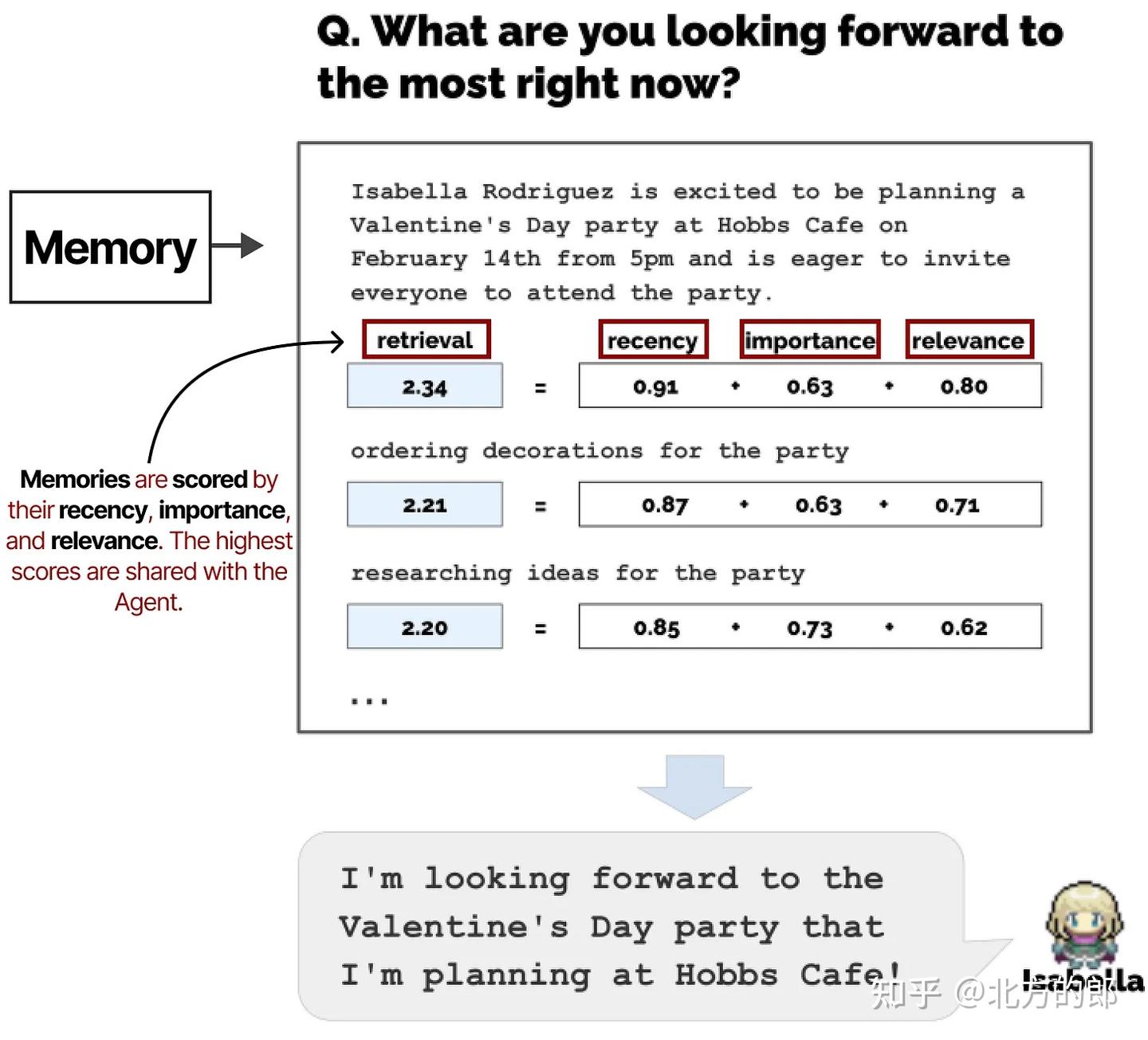
《生成智能体:人类行为的交互式模拟》论文的注释图表。
它们共同允许智能体自由地进行行为并相互交互。因此,智能体编排很少,因为它们没有特定的目标要努力实现。
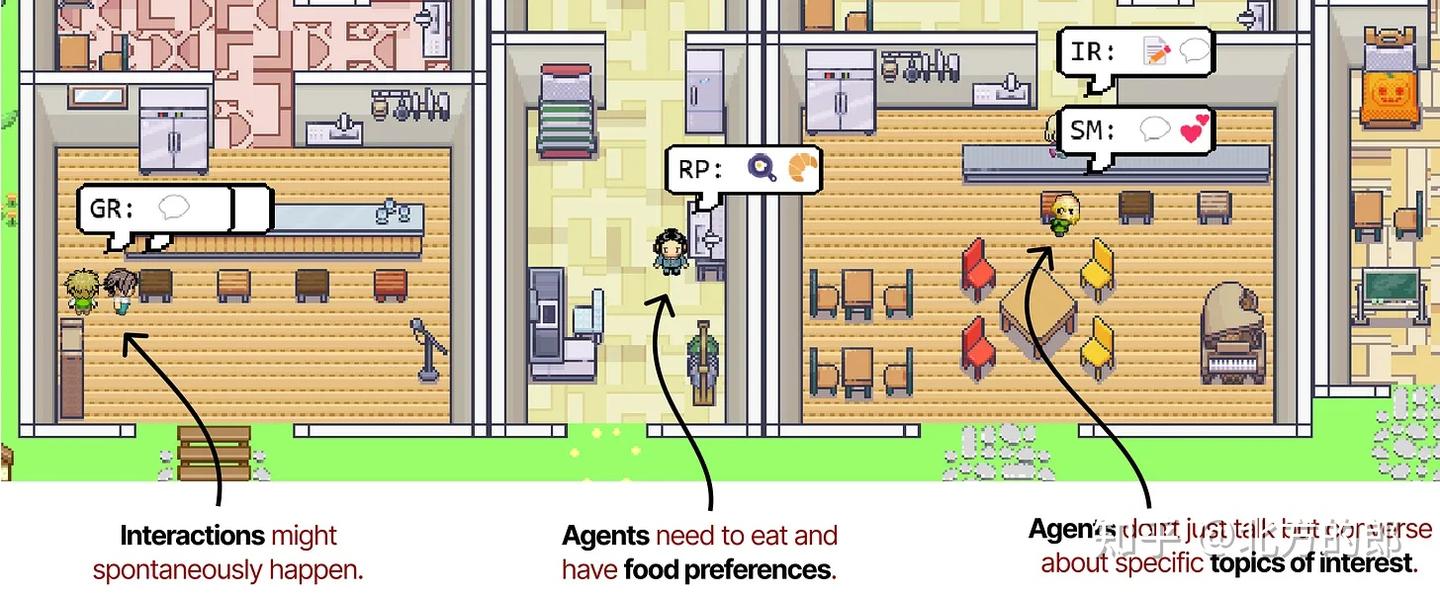
Annotated image from the interactive demo.
评估指标
这篇论文中有太多令人惊叹的信息片段,但我想强调它们的评估指标。
他们的评估涉及智能体行为的可信度作为主要指标,由人类评估者评分。
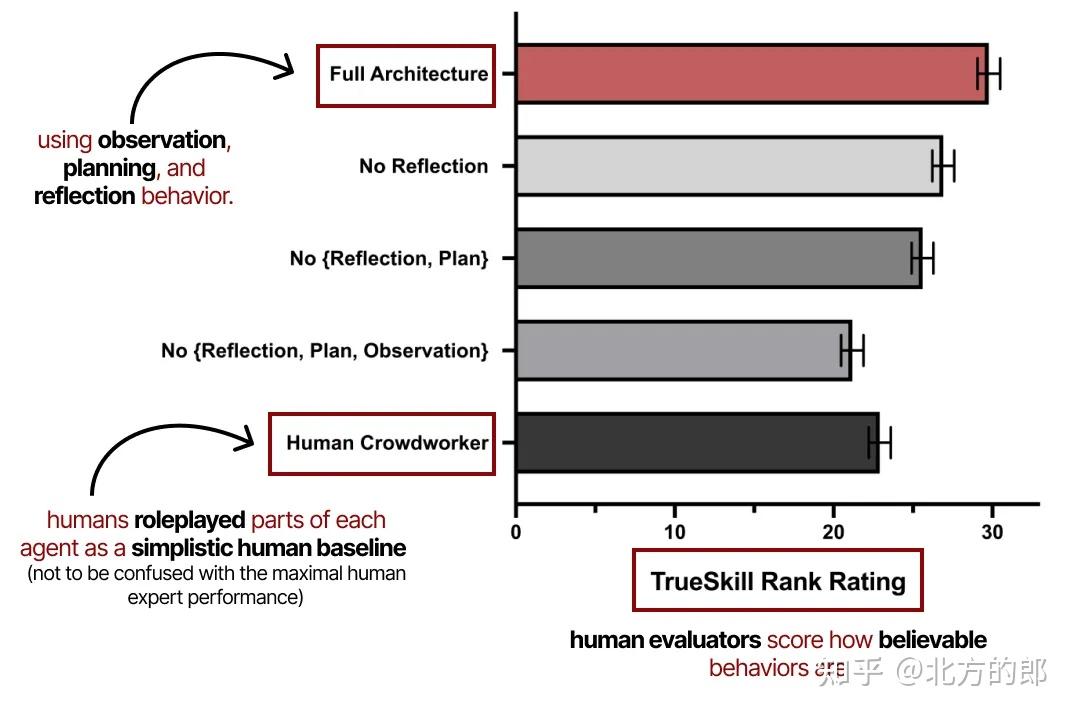
《生成智能体:人类行为的交互式模拟》论文的注释图表。
它展示了观察、规划和反思共同在这些生成智能体的性能中是多么重要。正如之前探索的,规划若没有反思行为是不完整的。
模块化框架
构成
环境感知+配置文件+记忆+规划+可用行动
无论你选择哪种框架来创建多智能体系统,它们通常由几个成分组成,包括其配置文件、对环境的感知、记忆、规划和可用行动。
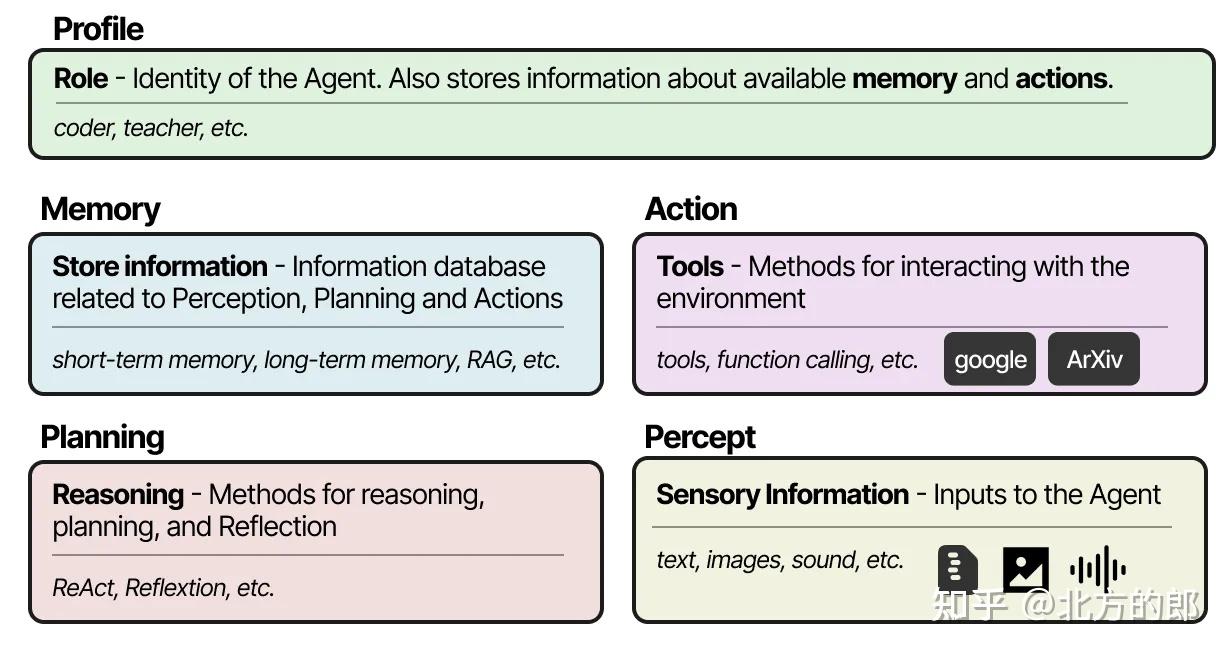
主流框架
依据主流博客总结,整理出目前主流的agent框架:langgraph, AutoGen, MetaGPT, ChatDev, Swarm, uagents。
对比
| 框架名称 | 技术特点 | 适用场景 | 社区活跃度 | 学习曲线 | 部署难度 |
|---|---|---|---|---|---|
langgraph | 循环控制、状态管理、人机交互 | 复杂工作流、多轮对话 | ⭐⭐⭐⭐ | 中等 | 中等 |
AutoGen | 多代理协作、模块化设计 | 团队协作、复杂任务分解 | ⭐⭐⭐⭐⭐ | 较高 | 中等 |
MetaGPT | 角色分工、软件开发流程 | 软件开发、项目管理 | ⭐⭐⭐⭐⭐ | 较高 | 较难 |
ChatDev | 开发流程自动化、多角色协作 | 软件开发、团队协作 | ⭐⭐⭐⭐ | 中等 | 中等 |
Swarm | 轻量级、高度可控 | 独立功能开发、原型验证 | ⭐⭐⭐⭐ | 较低 | 简单 |
uagents | 去中心化、轻量级 | 分布式应用、物联网 | ⭐⭐⭐ | 较低 | 简单 |
适用领域
- 若要开发智能客服,需重点关注框架的对话管理与多轮交互能力,像
AutoGen的多代理对话模式、ChatDev 基于 LLM 的问答能力便能大放异彩,它们能让客服与客户流畅沟通,精准解答疑问。 - 要是致力于数据分析挖掘,
Swarm的集群智能、LangChain 的数据连接与处理能力就派上用场,可助力快速处理海量数据,洞察数据价值。 - 而开发智能写作辅助工具时,
MetaGPT的内容生成、ShortGPT 的自动化创作优势凸显,能为创作者提供灵感、优化文案。
开发资源&文档支持
开发资源也是关键考量。
- 小型团队或个人开发者:上手容易、文档丰富的 LangChain 是优选,其简洁的 API 与大量示例,能助开发者快速搭建原型;
- 大型团队有定制化、拓展需求:
AutoGen的模块化设计、ChatDev 的高度可定制性,则提供了广阔的发挥空间。
社区支持
社区支持不容忽视。活跃的社区意味着丰富的教程、及时的问题解答与持续的更新。LangChain+langgraph 在 GitHub 超 100k star,海量资源随时可取;MetaGPT 超 4万star,开发者交流频繁,能紧跟前沿趋势。
安全性
安全性更是重中之重。处理敏感数据,要确保框架有严格的数据加密、访问控制机制。
- 一些框架经大公司或权威机构验证,安全性有保障;
- 新出现框架则需深入研究代码、评估漏洞风险,
langgraph
核心特性
- 状态管理:提供有状态的多参与者应用程序构建能力
- 循环控制:支持复杂的循环和条件流程定义
- 细粒度控制:对应用程序流程和状态提供精确控制
- 内置持久性:支持高级人机循环和记忆功能
技术优势
- 基于 DAG 的解决方案
- 与 LangChain 和 LangSmith 无缝集成
- 支持流式输出和令牌流
- 完整的开发工具链(API、SDK、CLI、Studio)
应用场景
- 复杂工作流程自动化
- 多轮对话系统
- 人机协作场景
GitHub 星标:8k+ | 地址:github.com/langchain-ai/langgraph
AutoGen
核心特性
- 多代理协作:支持自主、可扩展的 AI 代理团队构建
- 模块化设计:可定制特定功能的代理组件
- 跨语言支持:同时支持 .NET 和 Python
- 事件驱动:基于事件的代理系统
技术架构
- 核心 API:实现消息传递和分布式运行时
- AgentChat API:适用于快速原型设计
- 扩展 API:支持第一方和第三方功能扩展
应用场景
- 团队协作系统
- 自动化翻译服务
- 智能内容生成
- 代码辅助开发
GitHub 星标:37K+ | 地址:github.com/microsoft/autogen
MetaGPT
核心特性
- 角色抽象:模拟完整软件开发团队角色
- 流程自动化:覆盖从需求分析到代码生成的全流程
- 协同决策:多角色智能体协作决策机制
开发流程
- 需求分析:产品经理进行市场调研和需求定义
- 架构设计:架构师负责系统架构规划
- 项目管理:项目经理进行资源调配和进度管理
- 代码实现:工程师团队协作开发
应用场景
- 软件项目自动化开发
- 技术方案生成
- 代码审查和优化
GitHub 星标:46K+ | 地址:github.com/geekan/MetaGPT
ChatDev
核心特性
- 流程自动化:自动化软件开发全生命周期
- 多角色协作:支持不同角色智能体的协同工作
- 原子化任务:将复杂任务分解为原子级对话
开发阶段
- 设计阶段:需求分析和技术选型
- 编码阶段:代码实现和界面设计
- 测试阶段:功能测试和质量保证
- 文档阶段:技术文档和用户手册生成
GitHub 星标:26K+ | 地址:github.com/OpenBMB/ChatDev
Swarm
核心特性
- 轻量级设计:简洁高效的框架结构
- 高度可控:精确的代理协调和执行控制
- 客户端运行:几乎完全在客户端执行
- 无状态设计:类似 Chat Completions API 的无状态特性
技术优势
- 简单的代理抽象和移交机制
- 易于测试和调试
- 灵活的功能扩展性
GitHub 星标:17K+ | 地址:github.com/openai/swarm
uagents
核心特性
- 去中心化:支持分布式智能体部署
- 轻量级:高效的资源利用
- 跨平台:支持多种设备环境
技术优势
- 简洁的开发接口
- 灵活的部署选项
- 强大的扩展性
应用场景
- 分布式应用开发
- 物联网智能控制
- 去中心化社交网络
GitHub 星标:1.2K+ | 地址:github.com/fetchai/uAgents